Commit bc6c183 introduced a bunch of discrepancies between what files
look like in the repo and what clang-format says they should look like.
However, there were already a few discrepancies prior to that. Most of
these discrepancies seemed to be unintentional, but a few of them were
load-bearing (e.g., a #include that violated header ordering needing
something to have been #defined by a 'later' #include.)
I opted to take what I hope is a relatively smooth-brained approach: I
reverted the .clang-format change, ran clang-format on the whole repo,
reapplied the .clang-format change, reran clang-format again, and then
reverted the commit that contained the first run. Thus the full effect
of this PR should only be to apply the changed formatting rules to the
repo, and from skimming the results, this seems to be the case.
My work can be checked by applying the short, manual commits, and then
rerunning the command listed in the autogenerated commits (those whose
messages I have prefixed auto:) and seeing if your results agree.
It might be that the other diffs should be fixed at some point but I'm
leaving that aside for now.
fd '\.c(c|pp)?$' --print0| xargs -0 clang-format -i
At least in neovim, `│vi:` is not recognized as a modeline because it
has no preceding whitespace. After fixing this, opening a file yields
an error because `net` is not an option. (`noet`, however, is.)
This change boosts SSL handshake performance from 2,627 to ~10,000 per
second which is the same level of performance as NGINX at establishing
secure connections. That's impressive if we consider that redbean is a
forking frontend application server. This was accomplished by:
1. Enabling either SSL session caching or SSL tickets. We choose to
use tickets since they reduce network round trips too and that's
a more important metric than wrk'ing localhost.
2. Fixing mbedtls_mpi_sub_abs() which is the most frequently called
function. It's called about 12,000 times during an SSL handshake
since it's the basis of most arithmetic operations like addition
and for some strange reason it was designed to make two needless
copies in addition to calling malloc and free. That's now fixed.
3. Improving TLS output buffering during the SSL handshake only, so
that only a single is write and read system call is needed until
blocking on the ping pong.
redbean will now do a better job wiping sensitive memory from a child
process as soon as it's not needed. The nice thing about fork is it's
much faster than reverse proxying so the goal is to use the different
address spaces along with setuid() to minimize the risk that a server
key will be compromised in the event that application code is hacked.
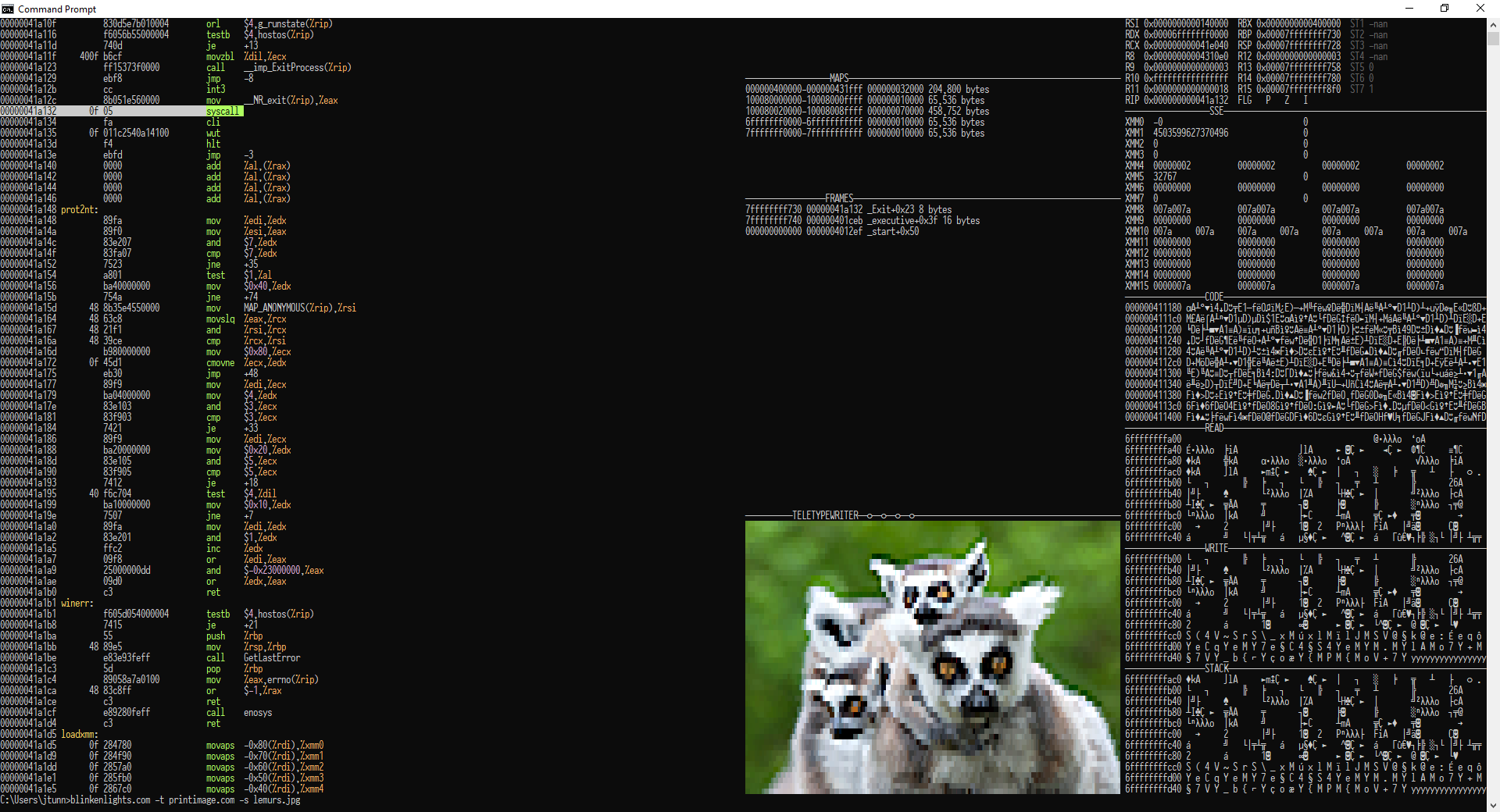
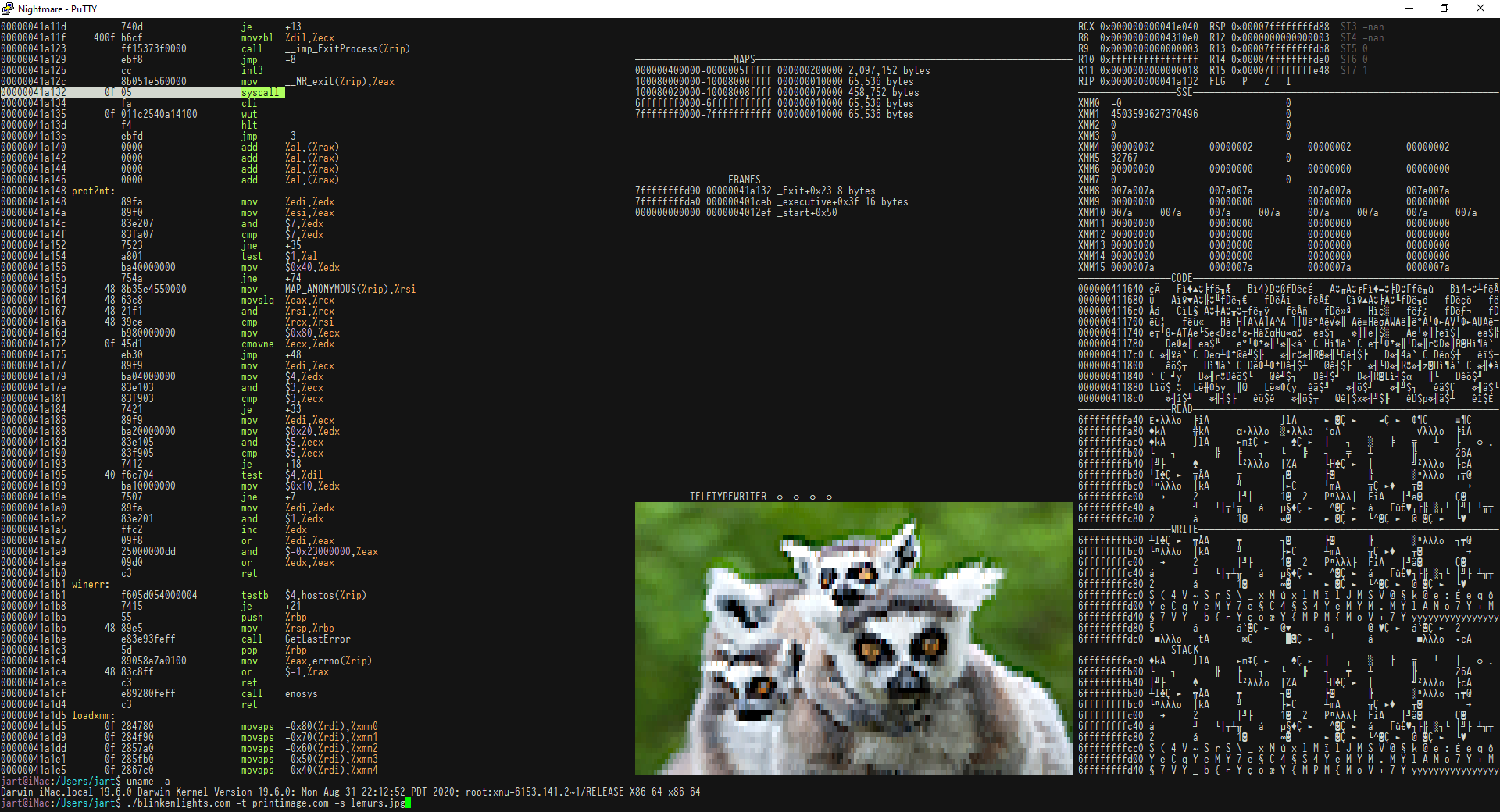
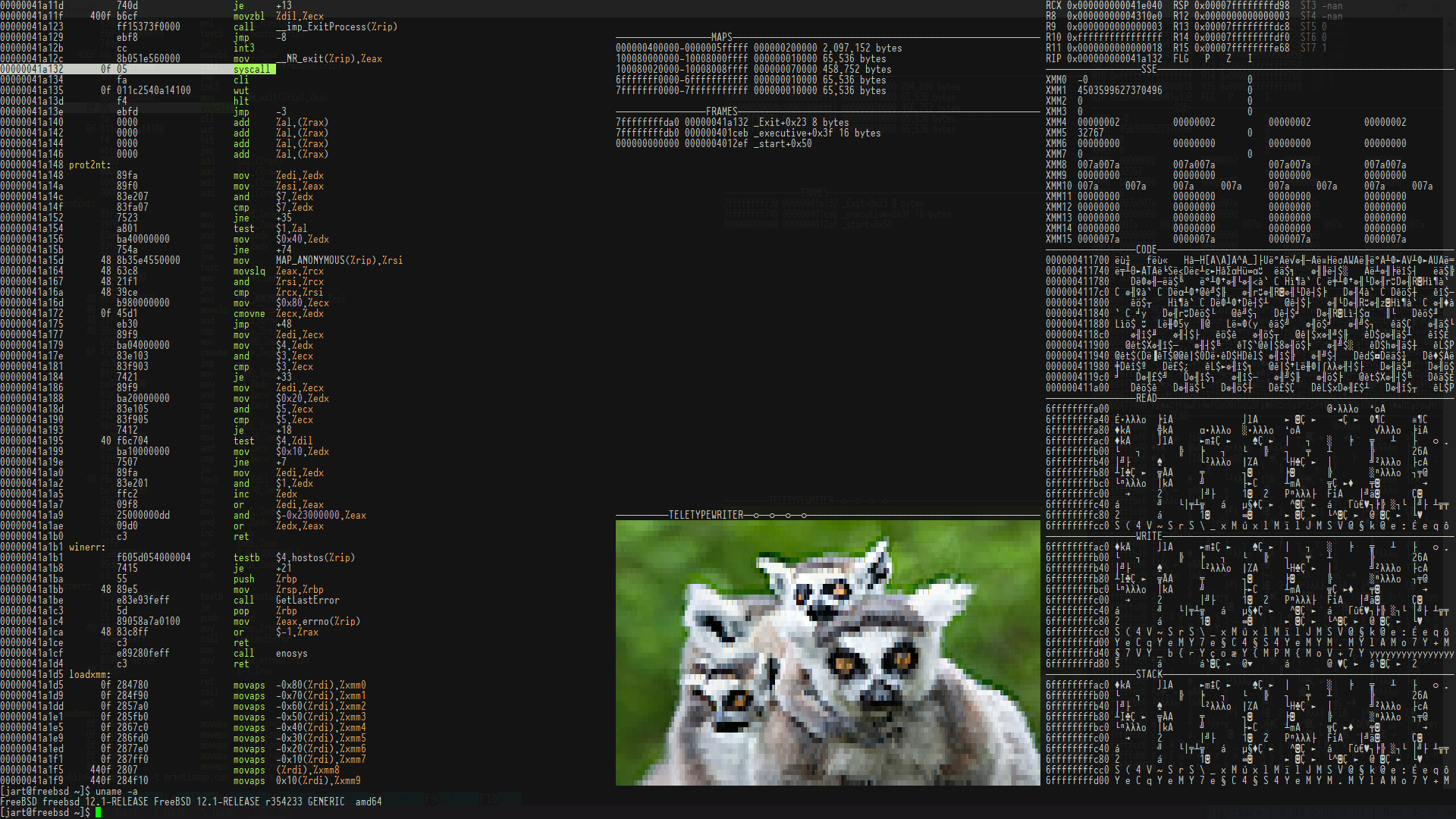
I wanted a tiny scriptable meltdown proof way to run userspace programs
and visualize how program execution impacts memory. It helps to explain
how things like Actually Portable Executable works. It can show you how
the GCC generated code is going about manipulating matrices and more. I
didn't feel fully comfortable with Qemu and Bochs because I'm not smart
enough to understand them. I wanted something like gVisor but with much
stronger levels of assurances. I wanted a single binary that'll run, on
all major operating systems with an embedded GPL barrier ZIP filesystem
that is tiny enough to transpile to JavaScript and run in browsers too.
https://justine.storage.googleapis.com/emulator625.mp4
{kind=link}
{kind=link}
{kind=link}
{kind=link}