Enrich and reword README.md (squashed)
Update README.md Update README.md Update README.md Update README.md Update README.md Update README.md Update README.md Update README.md Update README.md Update README.md
This commit is contained in:
parent
22ab495a79
commit
64d83e1fd5
1 changed files with 19 additions and 14 deletions
33
README.md
33
README.md
|
|
@ -25,24 +25,28 @@ only 18\% lower than that achieved by a top-tier server-grade A100 GPU.
|
|||
This significantly outperforms llama.cpp by up to 11.69x while retaining model accuracy.
|
||||
|
||||
## Feature
|
||||
PowerInfer is a fast and easy-to-use inference engine for deploying LLM locally. Interestingly, we observe that in ReLU LLM, every neuron is an expert! And a small subset of neurons consistently contributes to the output.
|
||||
PowerInfer is a high-speed and easy-to-use inference engine for deploying LLM locally. Interestingly, we observe that in ReLU LLM, every neuron is an expert! And a small subset of neurons consistently contributes to the output.
|
||||
PowerInfer is fast with:
|
||||
|
||||
- Exploiting the high locality in LLM infernece
|
||||
- Exploiting the high locality in LLM inference
|
||||
- Neuron-aware hybrid CPU/GPU sparse operator
|
||||
- Neuron granularity offloading
|
||||
|
||||
PowerInfer is flexible and easy to use with:
|
||||
|
||||
- Integration with popular [ReLU-sparse models](https://huggingface.co/SparseLLM)
|
||||
- Low-latency serving locally with single consumer-grade GPU
|
||||
- Low-latency serving locally with one single consumer-grade GPU
|
||||
|
||||
PowerInfer supports the following models:
|
||||
|
||||
- Falcon-40B model
|
||||
- Llama family models
|
||||
|
||||
The SparseLLM Team is currently converting the Mistral-7B model to a sparser version. Stay tuned!
|
||||
Now PowerInfer supports the following architectures:
|
||||
|
||||
- Intel CPU with AVX2 instructions
|
||||
- Nvidia GPU
|
||||
|
||||
|
||||
|
||||
|
||||
|
|
@ -55,7 +59,7 @@ The SparseLLM Team is currently converting the Mistral-7B model to a sparser ver
|
|||
### Get the Code
|
||||
|
||||
```bash
|
||||
git clone https://github.com/hodlen/PowerInfer
|
||||
git clone https://github.com/SJTU-IPADS/PowerInfer
|
||||
cd PowerInfer
|
||||
```
|
||||
### Build
|
||||
|
|
@ -79,12 +83,13 @@ cmake --build build --config Release
|
|||
```
|
||||
|
||||
## Model Weights
|
||||
|
||||
As for now, we have not released the predictor training code, we suggest you download the sparse model from huggingface in the following link.
|
||||
| Base Model | GGUF Format Link | Original Model |
|
||||
|------------|------------------|----------------|
|
||||
| LLaMA(ReLU)-2-7B | [PowerInfer/ReluLLaMA-7B-PowerInfer-GGUF](https://huggingface.co/PowerInfer/ReluLLaMA-13B-PowerInfer-GGUF) | [SparseLLM/ReluLLaMA-7B](https://huggingface.co/SparseLLM/ReluLLaMA-7B) |
|
||||
| LLaMA(ReLU)-2-7B | [PowerInfer/ReluLLaMA-7B-PowerInfer-GGUF](https://huggingface.co/PowerInfer/ReluLLaMA-7B-PowerInfer-GGUF) | [SparseLLM/ReluLLaMA-7B](https://huggingface.co/SparseLLM/ReluLLaMA-7B) |
|
||||
| LLaMA(ReLU)-2-13B | [PowerInfer/ReluLLaMA-13B-PowerInfer-GGUF](https://huggingface.co/PowerInfer/ReluLLaMA-13B-PowerInfer-GGUF) | [SparseLLM/ReluLLaMA-13B](https://huggingface.co/SparseLLM/ReluLLaMA-13B) |
|
||||
| Falcon(ReLU)-40B | [PowerInfer/ReluFalcon-40B-PowerInfer-GGUF](https://huggingface.co/PowerInfer/ReluLLaMA-13B-PowerInfer-GGUF) | [SparseLLM/ReluFalcon-40B](https://huggingface.co/SparseLLM/ReluFalcon-40B) |
|
||||
| Falcon(ReLU)-40B | [PowerInfer/ReluFalcon-40B-PowerInfer-GGUF](https://huggingface.co/PowerInfer/ReluFalcon-40B-PowerInfer-GGUF) | [SparseLLM/ReluFalcon-40B](https://huggingface.co/SparseLLM/ReluFalcon-40B) |
|
||||
| LLaMA(ReLU)-2-70B | [PowerInfer/ReluLLaMA-70B-PowerInfer-GGUF](https://huggingface.co/PowerInfer/ReluLLaMA-70B-PowerInfer-GGUF) | [SparseLLM/ReluLLaMA-70B](https://huggingface.co/SparseLLM/ReluLLaMA-70B) |
|
||||
|
||||
## Inference
|
||||
- If you just have CPU:
|
||||
|
|
@ -93,14 +98,14 @@ cmake --build build --config Release
|
|||
```
|
||||
- If you have CPU with one GPU:
|
||||
```bash
|
||||
./build/bin/main -m /PATH/TO/MODEL -n $(output_token_count) -t $(thread_num) -p $(prompt)
|
||||
./build/bin/main -m /PATH/TO/MODEL -n $(output_token_count) -t $(thread_num) -p $(prompt) --vram-budget $(GPU_VRAM_OFFLOADING)
|
||||
```
|
||||
|
||||
As for now, it requires a offline-generated "GPU index" file to split FFNs on GPU. If you want to try it, please use the following instruction to generate the GPU index file:
|
||||
As for now, it requires an offline-generated "GPU index" file to split FFNs on GPU. If you want to try it, please use the following instructions to generate the GPU index file:
|
||||
```bash
|
||||
python scripts/export-gpu-split.py $(activation_count_path) $(output_idx_path) solver
|
||||
```
|
||||
Then, you can use the following instruction to run PowerInfer with GPU index:
|
||||
Then, you can use the following instructions to run PowerInfer with GPU index:
|
||||
```bash
|
||||
./build/bin/main -m /PATH/TO/MODEL -n $(output_token_count) -t $(thread_num) -p $(prompt) --gpu-index $(split_path)
|
||||
```
|
||||
|
|
@ -111,7 +116,7 @@ Then, you can use the following instruction to run PowerInfer with GPU index:
|
|||
|
||||
|
||||
|
||||
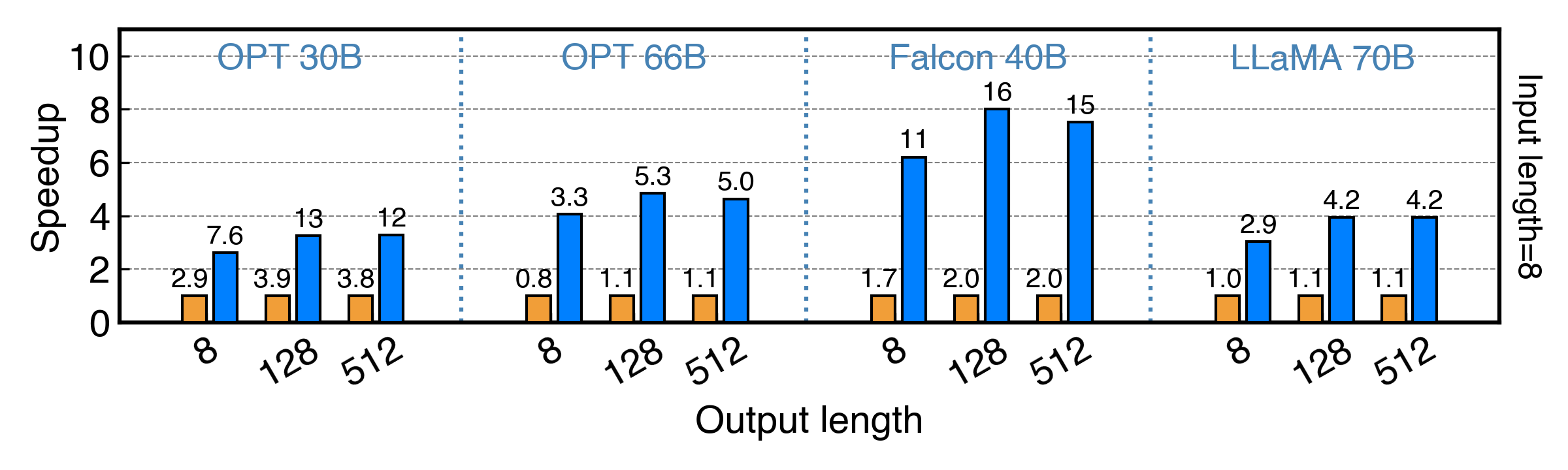
PowerInfer achieves up to 11x and 8x speedup for FP16 and INT4 model!
|
||||
PowerInfer achieves up to 11.69x and 8.00x speedup for FP16 and INT4 models!
|
||||
|
||||
## TODOs
|
||||
We will release the code and data in the following order, please stay tuned!
|
||||
|
|
@ -119,10 +124,10 @@ We will release the code and data in the following order, please stay tuned!
|
|||
- [x] Release core code of PowerInfer, supporting Llama-2, Falcon-40B.
|
||||
- [ ] Release perplexity evaluation code
|
||||
- [ ] Support Metal for Mac
|
||||
- [ ] Release code for OPT models
|
||||
- [ ] Release predictor training code
|
||||
- [ ] Support online split for FFN network
|
||||
- [ ] Support Multi-GPU
|
||||
|
||||
- [ ] Support Multi-GPU
|
||||
|
||||
|
||||
## Citation
|
||||
|
|
|
|||
Loading…
Add table
Add a link
Reference in a new issue