|
|
||
|---|---|---|
| .github/workflows | ||
| .gitignore | ||
| chat.cpp | ||
| CMakeLists.txt | ||
| convert-pth-to-ggml.py | ||
| ggml.c | ||
| ggml.h | ||
| LICENSE | ||
| Makefile | ||
| quantize.cpp | ||
| quantize.sh | ||
| README.md | ||
| screencast.gif | ||
| utils.cpp | ||
| utils.h | ||
{kind=link}
Alpaca.cpp
Run a fast ChatGPT-like model locally on your device. The screencast below is not sped up and running on an M2 Macbook Air with 4GB of weights.
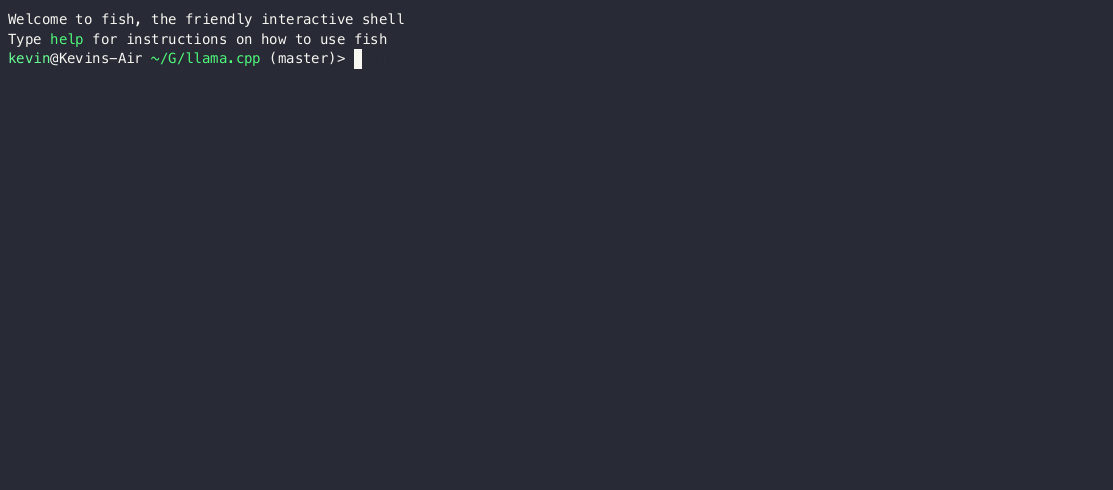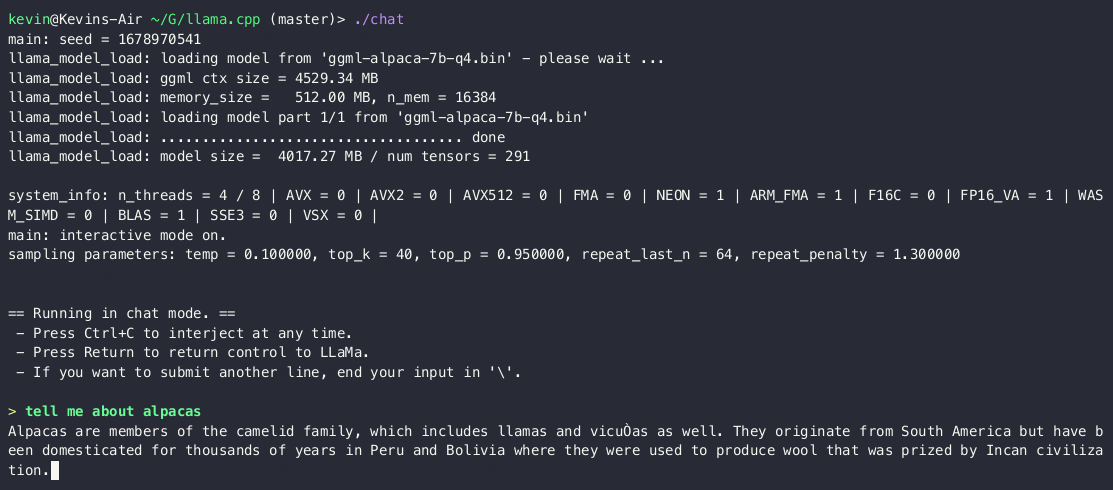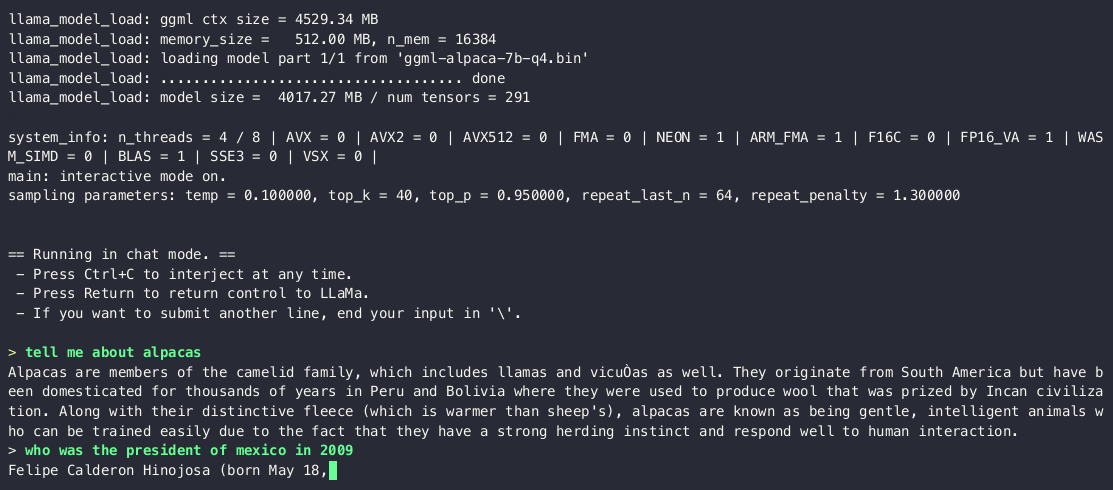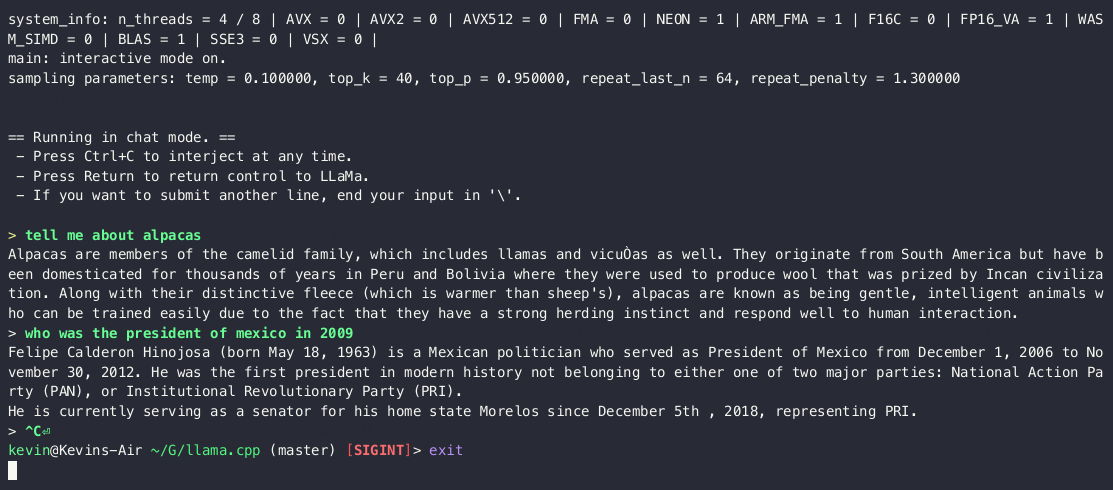
This combines the LLaMA foundation model with an open reproduction of Stanford Alpaca a fine-tuning of the base model to obey instructions (akin to the RLHF used to train ChatGPT).
Get started
git clone https://github.com/antimatter15/alpaca.cpp
cd alpaca.cpp
make chat
./chat
You can download the weights for ggml-alpaca-7b-14.bin with BitTorrent magnet:?xt=urn:btih:5aaceaec63b03e51a98f04fd5c42320b2a033010&dn=ggml-alpaca-7b-q4.bin&tr=udp%3A%2F%2Ftracker.opentrackr.org%3A1337%2Fannounce&tr=udp%3A%2F%2Fopentracker.i2p.rocks%3A6969%2Fannounce
Alternatively you can download them with IPFS.
# any of these will work
wget -O ggml-alpaca-7b-q4.bin -c https://gateway.estuary.tech/gw/ipfs/QmQ1bf2BTnYxq73MFJWu1B7bQ2UD6qG7D7YDCxhTndVkPC
wget -O ggml-alpaca-7b-q4.bin -c https://ipfs.io/ipfs/QmQ1bf2BTnYxq73MFJWu1B7bQ2UD6qG7D7YDCxhTndVkPC
wget -O ggml-alpaca-7b-q4.bin -c https://cloudflare-ipfs.com/ipfs/QmQ1bf2BTnYxq73MFJWu1B7bQ2UD6qG7D7YDCxhTndVkPC
Save the ggml-alpaca-7b-14.bin file in the same directory as your ./chat executable.
The weights are based on the published fine-tunes from alpaca-lora, converted back into a pytorch checkpoint with a modified script and then quantized with llama.cpp the regular way.
Credit
This combines Facebook's LLaMA, Stanford Alpaca, alpaca-lora (which uses Jason Phang's implementation of LLaMA on top of Hugging Face Transformers), and a modified version of llama.cpp by Georgi Gerganov. The chat implementation is based on Matvey Soloviev's Interactive Mode for llama.cpp. Inspired by Simon Willison's getting started guide for LLaMA.
Disclaimer
Note that the model weights are only to be used for research purposes, as they are derivative of LLaMA, and uses the published instruction data from the Stanford Alpaca project which is generated by OpenAI, which itself disallows the usage of its outputs to train competing models.