| .devops | ||
| .github | ||
| ci | ||
| docs | ||
| examples | ||
| include | ||
| lib | ||
| media | ||
| otherarch | ||
| spm-headers | ||
| .editorconfig | ||
| .flake8 | ||
| .gitignore | ||
| .pre-commit-config.yaml | ||
| build-info.h | ||
| clblast.dll | ||
| CMakeLists.txt | ||
| convert-lora-to-ggml.py | ||
| convert-pth-to-ggml.py | ||
| convert.py | ||
| cudart64_110.dll | ||
| export_state_dict_checkpoint.py | ||
| expose.cpp | ||
| expose.h | ||
| ggml-cuda.cu | ||
| ggml-cuda.h | ||
| ggml-metal.h | ||
| ggml-metal.m | ||
| ggml-metal.metal | ||
| ggml-mpi.c | ||
| ggml-mpi.h | ||
| ggml-opencl.cpp | ||
| ggml-opencl.h | ||
| ggml.c | ||
| ggml.h | ||
| gpttype_adapter.cpp | ||
| k_quants.c | ||
| k_quants.h | ||
| klite.embd | ||
| koboldcpp.py | ||
| libopenblas.dll | ||
| LICENSE.md | ||
| llama-util.h | ||
| llama.cpp | ||
| llama.h | ||
| make_old_pyinstaller.bat | ||
| make_old_pyinstaller_cuda.bat | ||
| make_pyinstaller.bat | ||
| make_pyinstaller.sh | ||
| Makefile | ||
| MIT_LICENSE_GGML_LLAMACPP_ONLY | ||
| model_adapter.cpp | ||
| model_adapter.h | ||
| msvcp140.dll | ||
| niko.ico | ||
| nikogreen.ico | ||
| Package.swift | ||
| README.md | ||
| Remote-Link.cmd | ||
| requirements.txt | ||
| rwkv_vocab.embd | ||
| rwkv_world_vocab.embd | ||
| vcruntime140.dll | ||
| vcruntime140_1.dll | ||
koboldcpp
A self contained distributable from Concedo that exposes llama.cpp function bindings, allowing it to be used via a simulated Kobold API endpoint.
What does it mean? You get llama.cpp with a fancy UI, persistent stories, editing tools, save formats, memory, world info, author's note, characters, scenarios and everything Kobold and Kobold Lite have to offer. In a tiny package around 20 MB in size, excluding model weights.
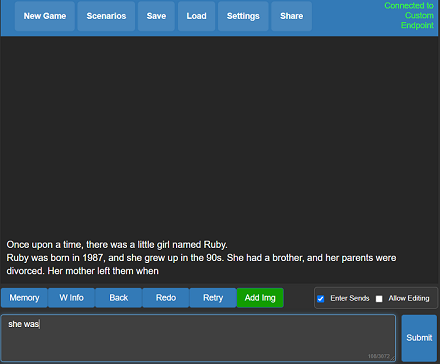
Usage
- Download the latest .exe release here or clone the git repo.
- Windows binaries are provided in the form of koboldcpp.exe, which is a pyinstaller wrapper for a few .dll files and koboldcpp.py. If you feel concerned, you may prefer to rebuild it yourself with the provided makefiles and scripts.
- Weights are not included, you can use the official llama.cpp
quantize.exeto generate them from your official weight files (or download them from other places such as TheBloke's Huggingface. - To run, execute koboldcpp.exe or drag and drop your quantized
ggml_model.binfile onto the .exe, and then connect with Kobold or Kobold Lite. If you're not on windows, then run the script KoboldCpp.py after compiling the libraries. - Launching with no command line arguments displays a GUI containing a subset of configurable settings. Generally you dont have to change much besides the
PresetsandGPU Layers. Read the--helpfor more info about each settings. - By default, you can connect to http://localhost:5001
- You can also run it using the command line
koboldcpp.exe [ggml_model.bin] [port]. For info, please checkkoboldcpp.exe --help - Default context size to small? Try
--contextsize 3072to 1.5x your context size! without much perplexity gain. Note that you'll have to increase the max context in the Kobold Lite UI as well (click and edit the number text field). - Big context too slow? Try the
--smartcontextflag to reduce prompt processing frequency. Also, you can try to run with your GPU using CLBlast, with--useclblastflag for a speedup - Want even more speedup? Combine
--useclblastwith--gpulayersto offload entire layers to the GPU! Much faster, but uses more VRAM. Experiment to determine number of layers to offload, and reduce by a few if you run out of memory. - If you are having crashes or issues, you can try turning off BLAS with the
--noblasflag. You can also try running in a non-avx2 compatibility mode with--noavx2. Lastly, you can try turning off mmap with--nommap.
For more information, be sure to run the program with the --help flag.
OSX and Linux
- You will have to compile your binaries from source. A makefile is provided, simply run
make - If you want you can also link your own install of OpenBLAS manually with
make LLAMA_OPENBLAS=1 - Alternatively, if you want you can also link your own install of CLBlast manually with
make LLAMA_CLBLAST=1, for this you will need to obtain and link OpenCL and CLBlast libraries.- For Arch Linux: Install
cblasopenblasandclblast. - For Debian: Install
libclblast-devandlibopenblas-dev.
- For Arch Linux: Install
- For a full featured build, do
make LLAMA_OPENBLAS=1 LLAMA_CLBLAST=1 LLAMA_CUBLAS=1 - After all binaries are built, you can run the python script with the command
koboldcpp.py [ggml_model.bin] [port] - Note: Many OSX users have found that the using Accelerate is actually faster than OpenBLAS. To try, you may wish to run with
--noblasand compare speeds.
Compiling on Windows
- You're encouraged to use the .exe released, but if you want to compile your binaries from source at Windows, the easiest way is:
- Use the latest release of w64devkit (https://github.com/skeeto/w64devkit). Be sure to use the "vanilla one", not i686 or other different stuff. If you try they will conflit with the precompiled libs!
- Make sure you are using the w64devkit integrated terminal, then run 'make' at the KoboldCpp source folder. This will create the .dll files.
- If you want to generate the .exe file, make sure you have the python module PyInstaller installed with pip ('pip install PyInstaller').
- Run the script make_pyinstaller.bat at a regular terminal (or Windows Explorer).
- The koboldcpp.exe file will be at your dist folder.
- If you wish to use your own version of the additional Windows libraries (OpenCL, CLBlast and OpenBLAS), you can do it with:
- OpenCL - tested with https://github.com/KhronosGroup/OpenCL-SDK . If you wish to compile it, follow the repository instructions. You will need vcpkg.
- CLBlast - tested with https://github.com/CNugteren/CLBlast . If you wish to compile it you will need to reference the OpenCL files. It will only generate the ".lib" file if you compile using MSVC.
- OpenBLAS - tested with https://github.com/xianyi/OpenBLAS .
- Move the respectives .lib files to the /lib folder of your project, overwriting the older files.
- Also, replace the existing versions of the corresponding .dll files located in the project directory root (e.g. libopenblas.dll).
- Make the KoboldCPP project using the instructions above.
Android (Termux) Alternative method
CuBLAS?
- If you're on Windows with an Nvidia GPU you can get CUDA support out of the box using the
--usecublasflag, make sure you select the correct .exe with CUDA support. - You can attempt a CuBLAS build with
LLAMA_CUBLAS=1or using the provided CMake file (best for visual studio users). If you use the CMake file to build, copy thekoboldcpp_cublas.dllgenerated into the same directory as thekoboldcpp.pyfile. If you are bundling executables, you may need to include CUDA dynamic libraries (such ascublasLt64_11.dllandcublas64_11.dll) in order for the executable to work correctly on a different PC. Note that support for CuBLAS is limited.
Considerations
- For Windows: No installation, single file executable, (It Just Works)
- Since v1.0.6, requires libopenblas, the prebuilt windows binaries are included in this repo. If not found, it will fall back to a mode without BLAS.
- Since v1.15, requires CLBlast if enabled, the prebuilt windows binaries are included in this repo. If not found, it will fall back to a mode without CLBlast.
- Since v1.33, you can set the context size to be above what the model supports officially. It does increases perplexity but should still work well below 4096 even on untuned models. (For GPT-NeoX, GPT-J, and LLAMA models) Customize this with
--ropeconfig. - I plan to keep backwards compatibility with ALL past llama.cpp AND alpaca.cpp models. But you are also encouraged to reconvert/update your models if possible for best results.
License
- The original GGML library and llama.cpp by ggerganov are licensed under the MIT License
- However, Kobold Lite is licensed under the AGPL v3.0 License
- The other files are also under the AGPL v3.0 License unless otherwise stated
Notes
- Generation delay scales linearly with original prompt length. If OpenBLAS is enabled then prompt ingestion becomes about 2-3x faster. This is automatic on windows, but will require linking on OSX and Linux. CLBlast speeds this up even further, and
--gpulayers+--useclblastmore so. - I have heard of someone claiming a false AV positive report. The exe is a simple pyinstaller bundle that includes the necessary python scripts and dlls to run. If this still concerns you, you might wish to rebuild everything from source code using the makefile, and you can rebuild the exe yourself with pyinstaller by using
make_pyinstaller.bat - Supported GGML models:
- LLAMA (All versions including ggml, ggmf, ggjt v1,v2,v3, openllama, gpt4all). Supports CLBlast and OpenBLAS acceleration for all versions.
- GPT-2 (All versions, including legacy f16, newer format + quanitzed, cerebras, starcoder) Supports CLBlast and OpenBLAS acceleration for newer formats, no GPU layer offload.
- GPT-J (All versions including legacy f16, newer format + quantized, pyg.cpp, new pygmalion, janeway etc.) Supports CLBlast and OpenBLAS acceleration for newer formats, no GPU layer offload.
- RWKV (all formats except Q4_1_O).
- GPT-NeoX / Pythia / StableLM / Dolly / RedPajama
- MPT models (ggjt v3)
- Basically every single current and historical GGML format that has ever existed should be supported, except for bloomz.cpp due to lack of demand.