Retooling to allow for docs build
Adding docs build to the Makefile Adding in Sven's changes to the Makefile Removing DS_store file Updating per Stephen's comments Update with Stephen's final comment Signed-off-by: Mary Anthony <mary@docker.com>
This commit is contained in:
parent
0eb50c18ea
commit
636a19b212
20 changed files with 43 additions and 1 deletions
2665
docs/spec/api.md
Normal file
2665
docs/spec/api.md
Normal file
File diff suppressed because it is too large
Load diff
796
docs/spec/api.md.tmpl
Normal file
796
docs/spec/api.md.tmpl
Normal file
|
|
@ -0,0 +1,796 @@
|
|||
# Docker Registry HTTP API V2
|
||||
|
||||
## Introduction
|
||||
|
||||
The _Docker Registry HTTP API_ is the protocol to facilitate distribution of
|
||||
images to the docker engine. It interacts with instances of the docker
|
||||
registry, which is a service to manage information about docker images and
|
||||
enable their distribution. The specification covers the operation of version 2
|
||||
of this API, known as _Docker Registry HTTP API V2_.
|
||||
|
||||
While the V1 registry protocol is usable, there are several problems with the
|
||||
architecture that have led to this new version. The main driver of this
|
||||
specification these changes to the docker the image format, covered in
|
||||
docker/docker#8093. The new, self-contained image manifest simplifies image
|
||||
definition and improves security. This specification will build on that work,
|
||||
leveraging new properties of the manifest format to improve performance,
|
||||
reduce bandwidth usage and decrease the likelihood of backend corruption.
|
||||
|
||||
For relevant details and history leading up to this specification, please see
|
||||
the following issues:
|
||||
|
||||
- [docker/docker#8093](https://github.com/docker/docker/issues/8093)
|
||||
- [docker/docker#9015](https://github.com/docker/docker/issues/9015)
|
||||
- [docker/docker-registry#612](https://github.com/docker/docker-registry/issues/612)
|
||||
|
||||
### Scope
|
||||
|
||||
This specification covers the URL layout and protocols of the interaction
|
||||
between docker registry and docker core. This will affect the docker core
|
||||
registry API and the rewrite of docker-registry. Docker registry
|
||||
implementations may implement other API endpoints, but they are not covered by
|
||||
this specification.
|
||||
|
||||
This includes the following features:
|
||||
|
||||
- Namespace-oriented URI Layout
|
||||
- PUSH/PULL registry server for V2 image manifest format
|
||||
- Resumable layer PUSH support
|
||||
- V2 Client library implementation
|
||||
|
||||
While authentication and authorization support will influence this
|
||||
specification, details of the protocol will be left to a future specification.
|
||||
Relevant header definitions and error codes are present to provide an
|
||||
indication of what a client may encounter.
|
||||
|
||||
#### Future
|
||||
|
||||
There are features that have been discussed during the process of cutting this
|
||||
specification. The following is an incomplete list:
|
||||
|
||||
- Immutable image references
|
||||
- Multiple architecture support
|
||||
- Migration from v2compatibility representation
|
||||
|
||||
These may represent features that are either out of the scope of this
|
||||
specification, the purview of another specification or have been deferred to a
|
||||
future version.
|
||||
|
||||
### Use Cases
|
||||
|
||||
For the most part, the use cases of the former registry API apply to the new
|
||||
version. Differentiating use cases are covered below.
|
||||
|
||||
#### Image Verification
|
||||
|
||||
A docker engine instance would like to run verified image named
|
||||
"library/ubuntu", with the tag "latest". The engine contacts the registry,
|
||||
requesting the manifest for "library/ubuntu:latest". An untrusted registry
|
||||
returns a manifest. Before proceeding to download the individual layers, the
|
||||
engine verifies the manifest's signature, ensuring that the content was
|
||||
produced from a trusted source and no tampering has occured. After each layer
|
||||
is downloaded, the engine verifies the digest of the layer, ensuring that the
|
||||
content matches that specified by the manifest.
|
||||
|
||||
#### Resumable Push
|
||||
|
||||
Company X's build servers lose connectivity to docker registry before
|
||||
completing an image layer transfer. After connectivity returns, the build
|
||||
server attempts to re-upload the image. The registry notifies the build server
|
||||
that the upload has already been partially attempted. The build server
|
||||
responds by only sending the remaining data to complete the image file.
|
||||
|
||||
#### Resumable Pull
|
||||
|
||||
Company X is having more connectivity problems but this time in their
|
||||
deployment datacenter. When downloading an image, the connection is
|
||||
interrupted before completion. The client keeps the partial data and uses http
|
||||
`Range` requests to avoid downloading repeated data.
|
||||
|
||||
#### Layer Upload De-duplication
|
||||
|
||||
Company Y's build system creates two identical docker layers from build
|
||||
processes A and B. Build process A completes uploading the layer before B.
|
||||
When process B attempts to upload the layer, the registry indicates that its
|
||||
not necessary because the layer is already known.
|
||||
|
||||
If process A and B upload the same layer at the same time, both operations
|
||||
will proceed and the first to complete will be stored in the registry (Note:
|
||||
we may modify this to prevent dogpile with some locking mechanism).
|
||||
|
||||
### Changes
|
||||
|
||||
The V2 specification has been written to work as a living document, specifying
|
||||
only what is certain and leaving what is not specified open or to future
|
||||
changes. Only non-conflicting additions should be made to the API and accepted
|
||||
changes should avoid preventing future changes from happening.
|
||||
|
||||
This section should be updated when changes are made to the specification,
|
||||
indicating what is different. Optionally, we may start marking parts of the
|
||||
specification to correspond with the versions enumerated here.
|
||||
|
||||
<dl>
|
||||
<dt>2.0.1</dt>
|
||||
<dd>
|
||||
<ul>
|
||||
<li>Added support for immutable manifest references in manifest endpoints.</li>
|
||||
<li>Deleting a manifest by tag has been deprecated.</li>
|
||||
<li>Specified `Docker-Content-Digest` header for appropriate entities.</li>
|
||||
<li>Added error code for unsupported operations.</li>
|
||||
</ul>
|
||||
</dd>
|
||||
|
||||
<dt>2.0</dt>
|
||||
<dd>
|
||||
This is the baseline specification.
|
||||
</dd>
|
||||
</dl>
|
||||
|
||||
## Overview
|
||||
|
||||
This section covers client flows and details of the API endpoints. The URI
|
||||
layout of the new API is structured to support a rich authentication and
|
||||
authorization model by leveraging namespaces. All endpoints will be prefixed
|
||||
by the API version and the repository name:
|
||||
|
||||
/v2/<name>/
|
||||
|
||||
For example, an API endpoint that will work with the `library/ubuntu`
|
||||
repository, the URI prefix will be:
|
||||
|
||||
/v2/library/ubuntu/
|
||||
|
||||
This scheme provides rich access control over various operations and methods
|
||||
using the URI prefix and http methods that can be controlled in variety of
|
||||
ways.
|
||||
|
||||
Classically, repository names have always been two path components where each
|
||||
path component is less than 30 characters. The V2 registry API does not
|
||||
enforce this. The rules for a repository name are as follows:
|
||||
|
||||
1. A repository name is broken up into _path components_. A component of a
|
||||
repository name must be at least two lowercase, alpha-numeric characters,
|
||||
optionally separated by periods, dashes or underscores. More strictly, it
|
||||
must match the regular expression `[a-z0-9]+(?:[._-][a-z0-9]+)*` and the
|
||||
matched result must be 2 or more characters in length.
|
||||
2. The name of a repository must have at least two path components, separated
|
||||
by a forward slash.
|
||||
3. The total length of a repository name, including slashes, must be less the
|
||||
256 characters.
|
||||
|
||||
These name requirements _only_ apply to the registry API and should accept a
|
||||
superset of what is supported by other docker ecosystem components.
|
||||
|
||||
All endpoints should support aggressive http caching, compression and range
|
||||
headers, where appropriate. The new API attempts to leverage HTTP semantics
|
||||
where possible but may break from standards to implement targeted features.
|
||||
|
||||
For detail on individual endpoints, please see the [_Detail_](#detail)
|
||||
section.
|
||||
|
||||
### Errors
|
||||
|
||||
Actionable failure conditions, covered in detail in their relevant sections,
|
||||
are reported as part of 4xx responses, in a json response body. One or more
|
||||
errors will be returned in the following format:
|
||||
|
||||
{
|
||||
"errors:" [{
|
||||
"code": <error identifier>,
|
||||
"message": <message describing condition>,
|
||||
"detail": <unstructured>
|
||||
},
|
||||
...
|
||||
]
|
||||
}
|
||||
|
||||
The `code` field will be a unique identifier, all caps with underscores by
|
||||
convention. The `message` field will be a human readable string. The optional
|
||||
`detail` field may contain arbitrary json data providing information the
|
||||
client can use to resolve the issue.
|
||||
|
||||
While the client can take action on certain error codes, the registry may add
|
||||
new error codes over time. All client implementations should treat unknown
|
||||
error codes as `UNKNOWN`, allowing future error codes to be added without
|
||||
breaking API compatibility. For the purposes of the specification error codes
|
||||
will only be added and never removed.
|
||||
|
||||
For a complete account of all error codes, please see the _Detail_ section.
|
||||
|
||||
### API Version Check
|
||||
|
||||
A minimal endpoint, mounted at `/v2/` will provide version support information
|
||||
based on its response statuses. The request format is as follows:
|
||||
|
||||
GET /v2/
|
||||
|
||||
If a `200 OK` response is returned, the registry implements the V2(.1)
|
||||
registry API and the client may proceed safely with other V2 operations.
|
||||
Optionally, the response may contain information about the supported paths in
|
||||
the response body. The client should be prepared to ignore this data.
|
||||
|
||||
If a `401 Unauthorized` response is returned, the client should take action
|
||||
based on the contents of the "WWW-Authenticate" header and try the endpoint
|
||||
again. Depending on access control setup, the client may still have to
|
||||
authenticate against different resources, even if this check succeeds.
|
||||
|
||||
If `404 Not Found` response status, or other unexpected status, is returned,
|
||||
the client should proceed with the assumption that the registry does not
|
||||
implement V2 of the API.
|
||||
|
||||
### Pulling An Image
|
||||
|
||||
An "image" is a combination of a JSON manifest and individual layer files. The
|
||||
process of pulling an image centers around retrieving these two components.
|
||||
|
||||
The first step in pulling an image is to retrieve the manifest. For reference,
|
||||
the relevant manifest fields for the registry are the following:
|
||||
|
||||
field | description |
|
||||
----------|------------------------------------------------|
|
||||
name | The name of the image. |
|
||||
tag | The tag for this version of the image. |
|
||||
fsLayers | A list of layer descriptors (including tarsum) |
|
||||
signature | A JWS used to verify the manifest content |
|
||||
|
||||
For more information about the manifest format, please see
|
||||
[docker/docker#8093](https://github.com/docker/docker/issues/8093).
|
||||
|
||||
When the manifest is in hand, the client must verify the signature to ensure
|
||||
the names and layers are valid. Once confirmed, the client will then use the
|
||||
tarsums to download the individual layers. Layers are stored in as blobs in
|
||||
the V2 registry API, keyed by their tarsum digest.
|
||||
|
||||
#### Pulling an Image Manifest
|
||||
|
||||
The image manifest can be fetched with the following url:
|
||||
|
||||
```
|
||||
GET /v2/<name>/manifests/<reference>
|
||||
```
|
||||
|
||||
The `name` and `reference` parameter identify the image and are required. The
|
||||
reference may include a tag or digest.
|
||||
|
||||
A `404 Not Found` response will be returned if the image is unknown to the
|
||||
registry. If the image exists and the response is successful, the image
|
||||
manifest will be returned, with the following format (see docker/docker#8093
|
||||
for details):
|
||||
|
||||
{
|
||||
"name": <name>,
|
||||
"tag": <tag>,
|
||||
"fsLayers": [
|
||||
{
|
||||
"blobSum": <tarsum>
|
||||
},
|
||||
...
|
||||
]
|
||||
],
|
||||
"history": <v1 images>,
|
||||
"signature": <JWS>
|
||||
}
|
||||
|
||||
The client should verify the returned manifest signature for authenticity
|
||||
before fetching layers.
|
||||
|
||||
#### Pulling a Layer
|
||||
|
||||
Layers are stored in the blob portion of the registry, keyed by tarsum digest.
|
||||
Pulling a layer is carried out by a standard http request. The URL is as
|
||||
follows:
|
||||
|
||||
GET /v2/<name>/blobs/<tarsum>
|
||||
|
||||
Access to a layer will be gated by the `name` of the repository but is
|
||||
identified uniquely in the registry by `tarsum`. The `tarsum` parameter is an
|
||||
opaque field, to be interpreted by the tarsum library.
|
||||
|
||||
This endpoint may issue a 307 (302 for <HTTP 1.1) redirect to another service
|
||||
for downloading the layer and clients should be prepared to handle redirects.
|
||||
|
||||
This endpoint should support aggressive HTTP caching for image layers. Support
|
||||
for Etags, modification dates and other cache control headers should be
|
||||
included. To allow for incremental downloads, `Range` requests should be
|
||||
supported, as well.
|
||||
|
||||
### Pushing An Image
|
||||
|
||||
Pushing an image works in the opposite order as a pull. After assembling the
|
||||
image manifest, the client must first push the individual layers. When the
|
||||
layers are fully pushed into the registry, the client should upload the signed
|
||||
manifest.
|
||||
|
||||
The details of each step of the process are covered in the following sections.
|
||||
|
||||
#### Pushing a Layer
|
||||
|
||||
All layer uploads use two steps to manage the upload process. The first step
|
||||
starts the upload in the registry service, returning a url to carry out the
|
||||
second step. The second step uses the upload url to transfer the actual data.
|
||||
Uploads are started with a POST request which returns a url that can be used
|
||||
to push data and check upload status.
|
||||
|
||||
The `Location` header will be used to communicate the upload location after
|
||||
each request. While it won't change in the this specification, clients should
|
||||
use the most recent value returned by the API.
|
||||
|
||||
##### Starting An Upload
|
||||
|
||||
To begin the process, a POST request should be issued in the following format:
|
||||
|
||||
```
|
||||
POST /v2/<name>/blobs/uploads/
|
||||
```
|
||||
|
||||
The parameters of this request are the image namespace under which the layer
|
||||
will be linked. Responses to this request are covered below.
|
||||
|
||||
##### Existing Layers
|
||||
|
||||
The existence of a layer can be checked via a `HEAD` request to the blob store
|
||||
API. The request should be formatted as follows:
|
||||
|
||||
```
|
||||
HEAD /v2/<name>/blobs/<digest>
|
||||
```
|
||||
|
||||
If the layer with the tarsum specified in `digest` is available, a 200 OK
|
||||
response will be received, with no actual body content (this is according to
|
||||
http specification). The response will look as follows:
|
||||
|
||||
```
|
||||
200 OK
|
||||
Content-Length: <length of blob>
|
||||
Docker-Content-Digest: <digest>
|
||||
```
|
||||
|
||||
When this response is received, the client can assume that the layer is
|
||||
already available in the registry under the given name and should take no
|
||||
further action to upload the layer. Note that the binary digests may differ
|
||||
for the existing registry layer, but the tarsums will be guaranteed to match.
|
||||
|
||||
##### Uploading the Layer
|
||||
|
||||
If the POST request is successful, a `202 Accepted` response will be returned
|
||||
with the upload URL in the `Location` header:
|
||||
|
||||
```
|
||||
202 Accepted
|
||||
Location: /v2/<name>/blobs/uploads/<uuid>
|
||||
Range: bytes=0-<offset>
|
||||
Content-Length: 0
|
||||
Docker-Upload-UUID: <uuid>
|
||||
```
|
||||
|
||||
The rest of the upload process can be carried out with the returned url,
|
||||
called the "Upload URL" from the `Location` header. All responses to the
|
||||
upload url, whether sending data or getting status, will be in this format.
|
||||
Though the URI format (`/v2/<name>/blobs/uploads/<uuid>`) for the `Location`
|
||||
header is specified, clients should treat it as an opaque url and should never
|
||||
try to assemble the it. While the `uuid` parameter may be an actual UUID, this
|
||||
proposal imposes no constraints on the format and clients should never impose
|
||||
any.
|
||||
|
||||
If clients need to correlate local upload state with remote upload state, the
|
||||
contents of the `Docker-Upload-UUID` header should be used. Such an id can be
|
||||
used to key the last used location header when implementing resumable uploads.
|
||||
|
||||
##### Upload Progress
|
||||
|
||||
The progress and chunk coordination of the upload process will be coordinated
|
||||
through the `Range` header. While this is a non-standard use of the `Range`
|
||||
header, there are examples of [similar approaches](https://developers.google.com/youtube/v3/guides/using_resumable_upload_protocol) in APIs with heavy use.
|
||||
For an upload that just started, for an example with a 1000 byte layer file,
|
||||
the `Range` header would be as follows:
|
||||
|
||||
```
|
||||
Range: bytes=0-0
|
||||
```
|
||||
|
||||
To get the status of an upload, issue a GET request to the upload URL:
|
||||
|
||||
```
|
||||
GET /v2/<name>/blobs/uploads/<uuid>
|
||||
Host: <registry host>
|
||||
```
|
||||
|
||||
The response will be similar to the above, except will return 204 status:
|
||||
|
||||
```
|
||||
204 No Content
|
||||
Location: /v2/<name>/blobs/uploads/<uuid>
|
||||
Range: bytes=0-<offset>
|
||||
Docker-Upload-UUID: <uuid>
|
||||
```
|
||||
|
||||
Note that the HTTP `Range` header byte ranges are inclusive and that will be
|
||||
honored, even in non-standard use cases.
|
||||
|
||||
##### Monolithic Upload
|
||||
|
||||
A monolithic upload is simply a chunked upload with a single chunk and may be
|
||||
favored by clients that would like to avoided the complexity of chunking. To
|
||||
carry out a "monolithic" upload, one can simply put the entire content blob to
|
||||
the provided URL:
|
||||
|
||||
```
|
||||
PUT /v2/<name>/blobs/uploads/<uuid>?digest=<tarsum>[&digest=sha256:<hex digest>]
|
||||
Content-Length: <size of layer>
|
||||
Content-Type: application/octet-stream
|
||||
|
||||
<Layer Binary Data>
|
||||
```
|
||||
|
||||
The "digest" parameter must be included with the PUT request. Please see the
|
||||
_Completed Upload_ section for details on the parameters and expected
|
||||
responses.
|
||||
|
||||
Additionally, the upload can be completed with a single `POST` request to
|
||||
the uploads endpoint, including the "size" and "digest" parameters:
|
||||
|
||||
```
|
||||
POST /v2/<name>/blobs/uploads/?digest=<tarsum>[&digest=sha256:<hex digest>]
|
||||
Content-Length: <size of layer>
|
||||
Content-Type: application/octet-stream
|
||||
|
||||
<Layer Binary Data>
|
||||
```
|
||||
|
||||
On the registry service, this should allocate a download, accept and verify
|
||||
the data and return the same response as the final chunk of an upload. If the
|
||||
POST request fails collecting the data in any way, the registry should attempt
|
||||
to return an error response to the client with the `Location` header providing
|
||||
a place to continue the download.
|
||||
|
||||
The single `POST` method is provided for convenience and most clients should
|
||||
implement `POST` + `PUT` to support reliable resume of uploads.
|
||||
|
||||
##### Chunked Upload
|
||||
|
||||
To carry out an upload of a chunk, the client can specify a range header and
|
||||
only include that part of the layer file:
|
||||
|
||||
```
|
||||
PATCH /v2/<name>/blobs/uploads/<uuid>
|
||||
Content-Length: <size of chunk>
|
||||
Content-Range: <start of range>-<end of range>
|
||||
Content-Type: application/octet-stream
|
||||
|
||||
<Layer Chunk Binary Data>
|
||||
```
|
||||
|
||||
There is no enforcement on layer chunk splits other than that the server must
|
||||
receive them in order. The server may enforce a minimum chunk size. If the
|
||||
server cannot accept the chunk, a `416 Requested Range Not Satisfiable`
|
||||
response will be returned and will include a `Range` header indicating the
|
||||
current status:
|
||||
|
||||
```
|
||||
416 Requested Range Not Satisfiable
|
||||
Location: /v2/<name>/blobs/uploads/<uuid>
|
||||
Range: 0-<last valid range>
|
||||
Content-Length: 0
|
||||
Docker-Upload-UUID: <uuid>
|
||||
```
|
||||
|
||||
If this response is received, the client should resume from the "last valid
|
||||
range" and upload the subsequent chunk. A 416 will be returned under the
|
||||
following conditions:
|
||||
|
||||
- Invalid Content-Range header format
|
||||
- Out of order chunk: the range of the next chunk must start immediately after
|
||||
the "last valid range" from the previous response.
|
||||
|
||||
When a chunk is accepted as part of the upload, a `202 Accepted` response will
|
||||
be returned, including a `Range` header with the current upload status:
|
||||
|
||||
```
|
||||
202 Accepted
|
||||
Location: /v2/<name>/blobs/uploads/<uuid>
|
||||
Range: bytes=0-<offset>
|
||||
Content-Length: 0
|
||||
Docker-Upload-UUID: <uuid>
|
||||
```
|
||||
|
||||
##### Completed Upload
|
||||
|
||||
For an upload to be considered complete, the client must submit a `PUT`
|
||||
request on the upload endpoint with a digest parameter. If it is not provided,
|
||||
the upload will not be considered complete. The format for the final chunk
|
||||
will be as follows:
|
||||
|
||||
```
|
||||
PUT /v2/<name>/blob/uploads/<uuid>?digest=<tarsum>[&digest=sha256:<hex digest>]
|
||||
Content-Length: <size of chunk>
|
||||
Content-Range: <start of range>-<end of range>
|
||||
Content-Type: application/octet-stream
|
||||
|
||||
<Last Layer Chunk Binary Data>
|
||||
```
|
||||
|
||||
Optionally, if all chunks have already been uploaded, a `PUT` request with a
|
||||
`digest` parameter and zero-length body may be sent to complete and validated
|
||||
the upload. Multiple "digest" parameters may be provided with different
|
||||
digests. The server may verify none or all of them but _must_ notify the
|
||||
client if the content is rejected.
|
||||
|
||||
When the last chunk is received and the layer has been validated, the client
|
||||
will receive a `201 Created` response:
|
||||
|
||||
```
|
||||
201 Created
|
||||
Location: /v2/<name>/blobs/<tarsum>
|
||||
Content-Length: 0
|
||||
Docker-Content-Digest: <digest>
|
||||
```
|
||||
|
||||
The `Location` header will contain the registry URL to access the accepted
|
||||
layer file. The `Docker-Content-Digest` header returns the canonical digest of
|
||||
the uploaded blob which may differ from the provided digest. Most clients may
|
||||
ignore the value but if it is used, the client should verify the value against
|
||||
the uploaded blob data.
|
||||
|
||||
###### Digest Parameter
|
||||
|
||||
The "digest" parameter is designed as an opaque parameter to support
|
||||
verification of a successful transfer. The initial version of the registry API
|
||||
will support a tarsum digest, in the standard tarsum format. For example, a
|
||||
HTTP URI parameter might be as follows:
|
||||
|
||||
```
|
||||
tarsum.v1+sha256:6c3c624b58dbbcd3c0dd82b4c53f04194d1247c6eebdaab7c610cf7d66709b3b
|
||||
```
|
||||
|
||||
Given this parameter, the registry will verify that the provided content does
|
||||
result in this tarsum. Optionally, the registry can support other other digest
|
||||
parameters for non-tarfile content stored as a layer. A regular hash digest
|
||||
might be specified as follows:
|
||||
|
||||
```
|
||||
sha256:6c3c624b58dbbcd3c0dd82b4c53f04194d1247c6eebdaab7c610cf7d66709b3b
|
||||
```
|
||||
|
||||
Such a parameter would be used to verify that the binary content (as opposed
|
||||
to the tar content) would be verified at the end of the upload process.
|
||||
|
||||
For the initial version, registry servers are only required to support the
|
||||
tarsum format.
|
||||
|
||||
##### Canceling an Upload
|
||||
|
||||
An upload can be cancelled by issuing a DELETE request to the upload endpoint.
|
||||
The format will be as follows:
|
||||
|
||||
```
|
||||
DELETE /v2/<name>/blobs/uploads/<uuid>
|
||||
```
|
||||
|
||||
After this request is issued, the upload uuid will no longer be valid and the
|
||||
registry server will dump all intermediate data. While uploads will time out
|
||||
if not completed, clients should issue this request if they encounter a fatal
|
||||
error but still have the ability to issue an http request.
|
||||
|
||||
##### Errors
|
||||
|
||||
If an 502, 503 or 504 error is received, the client should assume that the
|
||||
download can proceed due to a temporary condition, honoring the appropriate
|
||||
retry mechanism. Other 5xx errors should be treated as terminal.
|
||||
|
||||
If there is a problem with the upload, a 4xx error will be returned indicating
|
||||
the problem. After receiving a 4xx response (except 416, as called out above),
|
||||
the upload will be considered failed and the client should take appropriate
|
||||
action.
|
||||
|
||||
Note that the upload url will not be available forever. If the upload uuid is
|
||||
unknown to the registry, a `404 Not Found` response will be returned and the
|
||||
client must restart the upload process.
|
||||
|
||||
#### Pushing an Image Manifest
|
||||
|
||||
Once all of the layers for an image are uploaded, the client can upload the
|
||||
image manifest. An image can be pushed using the following request format:
|
||||
|
||||
PUT /v2/<name>/manifests/<reference>
|
||||
|
||||
{
|
||||
"name": <name>,
|
||||
"tag": <tag>,
|
||||
"fsLayers": [
|
||||
{
|
||||
"blobSum": <tarsum>
|
||||
},
|
||||
...
|
||||
]
|
||||
],
|
||||
"history": <v1 images>,
|
||||
"signature": <JWS>,
|
||||
...
|
||||
}
|
||||
|
||||
The `name` and `reference` fields of the response body must match those specified in
|
||||
the URL. The `reference` field may be a "tag" or a "digest".
|
||||
|
||||
If there is a problem with pushing the manifest, a relevant 4xx response will
|
||||
be returned with a JSON error message. Please see the _PUT Manifest section
|
||||
for details on possible error codes that may be returned.
|
||||
|
||||
If one or more layers are unknown to the registry, `BLOB_UNKNOWN` errors are
|
||||
returned. The `detail` field of the error response will have a `digest` field
|
||||
identifying the missing blob, which will be a tarsum. An error is returned for
|
||||
each unknown blob. The response format is as follows:
|
||||
|
||||
{
|
||||
"errors:" [{
|
||||
"code": "BLOB_UNKNOWN",
|
||||
"message": "blob unknown to registry",
|
||||
"detail": {
|
||||
"digest": <tarsum>
|
||||
}
|
||||
},
|
||||
...
|
||||
]
|
||||
}
|
||||
|
||||
#### Listing Image Tags
|
||||
|
||||
It may be necessary to list all of the tags under a given repository. The tags
|
||||
for an image repository can be retrieved with the following request:
|
||||
|
||||
GET /v2/<name>/tags/list
|
||||
|
||||
The response will be in the following format:
|
||||
|
||||
200 OK
|
||||
Content-Type: application/json
|
||||
|
||||
{
|
||||
"name": <name>,
|
||||
"tags": [
|
||||
<tag>,
|
||||
...
|
||||
]
|
||||
}
|
||||
|
||||
For repositories with a large number of tags, this response may be quite
|
||||
large, so care should be taken by the client when parsing the response to
|
||||
reduce copying.
|
||||
|
||||
### Deleting an Image
|
||||
|
||||
An image may be deleted from the registry via its `name` and `reference`. A
|
||||
delete may be issued with the following request format:
|
||||
|
||||
DELETE /v2/<name>/manifests/<reference>
|
||||
|
||||
For deletes, `reference` *must* be a digest or the delete will fail. If the
|
||||
image exists and has been successfully deleted, the following response will be
|
||||
issued:
|
||||
|
||||
202 Accepted
|
||||
Content-Length: None
|
||||
|
||||
If the image had already been deleted or did not exist, a `404 Not Found`
|
||||
response will be issued instead.
|
||||
|
||||
## Detail
|
||||
|
||||
> **Note**: This section is still under construction. For the purposes of
|
||||
> implementation, if any details below differ from the described request flows
|
||||
> above, the section below should be corrected. When they match, this note
|
||||
> should be removed.
|
||||
|
||||
The behavior of the endpoints are covered in detail in this section, organized
|
||||
by route and entity. All aspects of the request and responses are covered,
|
||||
including headers, parameters and body formats. Examples of requests and their
|
||||
corresponding responses, with success and failure, are enumerated.
|
||||
|
||||
> **Note**: The sections on endpoint detail are arranged with an example
|
||||
> request, a description of the request, followed by information about that
|
||||
> request.
|
||||
|
||||
A list of methods and URIs are covered in the table below:
|
||||
|
||||
|Method|Path|Entity|Description|
|
||||
-------|----|------|------------
|
||||
{{range $route := .RouteDescriptors}}{{range $method := .Methods}}| {{$method.Method}} | `{{$route.Path|prettygorilla}}` | {{$route.Entity}} | {{$method.Description}} |
|
||||
{{end}}{{end}}
|
||||
|
||||
The detail for each endpoint is covered in the following sections.
|
||||
|
||||
### Errors
|
||||
|
||||
The error codes encountered via the API are enumerated in the following table:
|
||||
|
||||
|Code|Message|Description|
|
||||
-------|----|------|------------
|
||||
{{range $err := .ErrorDescriptors}} `{{$err.Value}}` | {{$err.Message}} | {{$err.Description|removenewlines}}
|
||||
{{end}}
|
||||
|
||||
{{range $route := .RouteDescriptors}}
|
||||
### {{.Entity}}
|
||||
|
||||
{{.Description}}
|
||||
|
||||
{{range $method := $route.Methods}}
|
||||
|
||||
#### {{.Method}} {{$route.Entity}}
|
||||
|
||||
{{.Description}}
|
||||
|
||||
{{if .Requests}}{{range .Requests}}{{if .Name}}
|
||||
##### {{.Name}}{{end}}
|
||||
|
||||
```
|
||||
{{$method.Method}} {{$route.Path|prettygorilla}}{{if .QueryParameters}}?{{range .QueryParameters}}{{.Name}}={{.Format}}{{end}}{{end}}{{range .Headers}}
|
||||
{{.Name}}: {{.Format}}{{end}}{{if .Body.ContentType}}
|
||||
Content-Type: {{.Body.ContentType}}{{end}}{{if .Body.Format}}
|
||||
|
||||
{{.Body.Format}}{{end}}
|
||||
```
|
||||
|
||||
{{.Description}}
|
||||
|
||||
{{if or .Headers .PathParameters .QueryParameters}}
|
||||
The following parameters should be specified on the request:
|
||||
|
||||
|Name|Kind|Description|
|
||||
|----|----|-----------|
|
||||
{{range .Headers}}|`{{.Name}}`|header|{{.Description}}|
|
||||
{{end}}{{range .PathParameters}}|`{{.Name}}`|path|{{.Description}}|
|
||||
{{end}}{{range .QueryParameters}}|`{{.Name}}`|query|{{.Description}}|
|
||||
{{end}}{{end}}
|
||||
|
||||
{{if .Successes}}
|
||||
{{range .Successes}}
|
||||
###### On Success: {{if .Name}}{{.Name}}{{else}}{{.StatusCode | statustext}}{{end}}
|
||||
|
||||
```
|
||||
{{.StatusCode}} {{.StatusCode | statustext}}{{range .Headers}}
|
||||
{{.Name}}: {{.Format}}{{end}}{{if .Body.ContentType}}
|
||||
Content-Type: {{.Body.ContentType}}{{end}}{{if .Body.Format}}
|
||||
|
||||
{{.Body.Format}}{{end}}
|
||||
```
|
||||
|
||||
{{.Description}}
|
||||
|
||||
{{if .Headers}}The following headers will be returned with the response:
|
||||
|
||||
|Name|Description|
|
||||
|----|-----------|
|
||||
{{range .Headers}}|`{{.Name}}`|{{.Description}}|
|
||||
{{end}}{{end}}{{end}}{{end}}
|
||||
|
||||
{{if .Failures}}
|
||||
{{range .Failures}}
|
||||
###### On Failure: {{if .Name}}{{.Name}}{{else}}{{.StatusCode | statustext}}{{end}}
|
||||
|
||||
```
|
||||
{{.StatusCode}} {{.StatusCode | statustext}}{{range .Headers}}
|
||||
{{.Name}}: {{.Format}}{{end}}{{if .Body.ContentType}}
|
||||
Content-Type: {{.Body.ContentType}}{{end}}{{if .Body.Format}}
|
||||
|
||||
{{.Body.Format}}{{end}}
|
||||
```
|
||||
|
||||
{{.Description}}
|
||||
{{if .Headers}}
|
||||
The following headers will be returned on the response:
|
||||
|
||||
|Name|Description|
|
||||
|----|-----------|
|
||||
{{range .Headers}}|`{{.Name}}`|{{.Description}}|
|
||||
{{end}}{{end}}
|
||||
|
||||
{{if .ErrorCodes}}
|
||||
The error codes that may be included in the response body are enumerated below:
|
||||
|
||||
|Code|Message|Description|
|
||||
-------|----|------|------------
|
||||
{{range $err := .ErrorCodes}}| `{{$err}}` | {{$err.Descriptor.Message}} | {{$err.Descriptor.Description|removenewlines}} |
|
||||
{{end}}
|
||||
|
||||
{{end}}{{end}}{{end}}{{end}}{{end}}{{end}}
|
||||
|
||||
{{end}}
|
||||
413
docs/spec/auth/token.md
Normal file
413
docs/spec/auth/token.md
Normal file
|
|
@ -0,0 +1,413 @@
|
|||
# Docker Registry v2 authentication via central service
|
||||
|
||||
Today a Docker Registry can run in standalone mode in which there are no
|
||||
authorization checks. While adding your own HTTP authorization requirements in
|
||||
a proxy placed between the client and the registry can give you greater access
|
||||
control, we'd like a native authorization mechanism that's public key based
|
||||
with access control lists managed separately with the ability to have fine
|
||||
granularity in access control on a by-key, by-user, by-namespace, and
|
||||
by-repository basis. In v1 this can be configured by specifying an
|
||||
`index_endpoint` in the registry's config. Clients present tokens generated by
|
||||
the index and tokens are validated on-line by the registry with every request.
|
||||
This results in a complex authentication and authorization loop that occurs
|
||||
with every registry operation. Some people are very familiar with this image:
|
||||
|
||||

|
||||
|
||||
The above image outlines the 6-step process in accessing the Official Docker
|
||||
Registry.
|
||||
|
||||
1. Contact the Docker Hub to know where I should download “samalba/busybox”
|
||||
2. Docker Hub replies:
|
||||
a. samalba/busybox is on Registry A
|
||||
b. here are the checksums for samalba/busybox (for all layers)
|
||||
c. token
|
||||
3. Contact Registry A to receive the layers for samalba/busybox (all of them to
|
||||
the base image). Registry A is authoritative for “samalba/busybox” but keeps
|
||||
a copy of all inherited layers and serve them all from the same location.
|
||||
4. Registry contacts Docker Hub to verify if token/user is allowed to download
|
||||
images.
|
||||
5. Docker Hub returns true/false lettings registry know if it should proceed or
|
||||
error out.
|
||||
6. Get the payload for all layers.
|
||||
|
||||
The goal of this document is to outline a way to eliminate steps 4 and 5 from
|
||||
the above process by using cryptographically signed tokens and no longer
|
||||
require the client to authenticate each request with a username and password
|
||||
stored locally in plain text.
|
||||
|
||||
The new registry workflow is more like this:
|
||||
|
||||
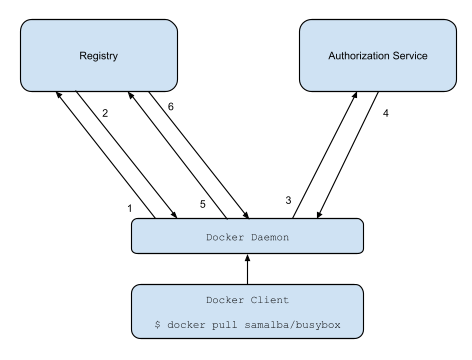
|
||||
|
||||
1. Attempt to begin a push/pull operation with the registry.
|
||||
2. If the registry requires authorization it will return a `401 Unauthorized`
|
||||
HTTP response with information on how to authenticate.
|
||||
3. The registry client makes a request to the authorization service for a
|
||||
signed JSON Web Token.
|
||||
4. The authorization service returns a token.
|
||||
5. The client retries the original request with the token embedded in the
|
||||
request header.
|
||||
6. The Registry authorizes the client and begins the push/pull session as
|
||||
usual.
|
||||
|
||||
## Requirements
|
||||
|
||||
- Registry Clients capable of generating key pairs which can be used to
|
||||
authenticate to an authorization server.
|
||||
- An authorization server capable of managing user accounts, their public keys,
|
||||
and access controls to their resources hosted by any given service (such as
|
||||
repositories in a Docker Registry).
|
||||
- A Docker Registry capable of trusting the authorization server to sign tokens
|
||||
which clients can use for authorization and the ability to verify these
|
||||
tokens for single use or for use during a sufficiently short period of time.
|
||||
|
||||
## Authorization Server Endpoint Descriptions
|
||||
|
||||
This document borrows heavily from the [JSON Web Token Draft Spec](https://tools.ietf.org/html/draft-ietf-oauth-json-web-token-32)
|
||||
|
||||
The described server is meant to serve as a user account and key manager and a
|
||||
centralized access control list for resources hosted by other services which
|
||||
wish to authenticate and manage authorizations using this services accounts and
|
||||
their public keys.
|
||||
|
||||
Such a service could be used by the official docker registry to authenticate
|
||||
clients and verify their authorization to docker image repositories.
|
||||
|
||||
Docker will need to be updated to interact with an authorization server to get
|
||||
an authorization token.
|
||||
|
||||
## How to authenticate
|
||||
|
||||
Today, registry clients first contact the index to initiate a push or pull.
|
||||
For v2, clients should contact the registry first. If the registry server
|
||||
requires authentication it will return a `401 Unauthorized` response with a
|
||||
`WWW-Authenticate` header detailing how to authenticate to this registry.
|
||||
|
||||
For example, say I (username `jlhawn`) am attempting to push an image to the
|
||||
repository `samalba/my-app`. For the registry to authorize this, I either need
|
||||
`push` access to the `samalba/my-app` repository or `push` access to the whole
|
||||
`samalba` namespace in general. The registry will first return this response:
|
||||
|
||||
```
|
||||
HTTP/1.1 401 Unauthorized
|
||||
WWW-Authenticate: Bearer realm="https://auth.docker.com/v2/token/",service="registry.docker.com",scope="repository:samalba/my-app:push"
|
||||
```
|
||||
|
||||
This format is documented in [Section 3 of RFC 6750: The OAuth 2.0 Authorization Framework: Bearer Token Usage](https://tools.ietf.org/html/rfc6750#section-3)
|
||||
|
||||
The client will then know to make a `GET` request to the URL
|
||||
`https://auth.docker.com/v2/token/` using the `service` and `scope` values from
|
||||
the `WWW-Authenticate` header.
|
||||
|
||||
## Requesting a Token
|
||||
|
||||
#### Query Parameters
|
||||
|
||||
<dl>
|
||||
<dt>
|
||||
<code>service</code>
|
||||
</dt>
|
||||
<dd>
|
||||
The name of the service which hosts the resource.
|
||||
</dd>
|
||||
<dt>
|
||||
<code>scope</code>
|
||||
</dt>
|
||||
<dd>
|
||||
The resource in question, formatted as one of the space-delimited
|
||||
entries from the <code>scope</code> parameters from the <code>WWW-Authenticate</code> header
|
||||
shown above. This query parameter should be specified multiple times if
|
||||
there is more than one <code>scope</code> entry from the <code>WWW-Authenticate</code>
|
||||
header. The above example would be specified as:
|
||||
<code>scope=repository:samalba/my-app:push</code>.
|
||||
</dd>
|
||||
<dt>
|
||||
<code>account</code>
|
||||
</dt>
|
||||
<dd>
|
||||
The name of the account which the client is acting as. Optional if it
|
||||
can be inferred from client authentication.
|
||||
</dd>
|
||||
</dl>
|
||||
|
||||
#### Description
|
||||
|
||||
Requests an authorization token for access to a specific resource hosted by a
|
||||
specific service provider. Requires the client to authenticate either using a
|
||||
TLS client certificate or using basic authentication (or any other kind of
|
||||
digest/challenge/response authentication scheme if the client doesn't support
|
||||
TLS client certs). If the key in the client certificate is linked to an account
|
||||
then the token is issued for that account key. If the key in the certificate is
|
||||
linked to multiple accounts then the client must specify the `account` query
|
||||
parameter. The returned token is in JWT (JSON Web Token) format, signed using
|
||||
the authorization server's private key.
|
||||
|
||||
#### Example
|
||||
|
||||
For this example, the client makes an HTTP request to the following endpoint
|
||||
over TLS using a client certificate with the server being configured to allow a
|
||||
non-verified issuer during the handshake (i.e., a self-signed client cert is
|
||||
okay).
|
||||
|
||||
```
|
||||
GET /v2/token/?service=registry.docker.com&scope=repository:samalba/my-app:push&account=jlhawn HTTP/1.1
|
||||
Host: auth.docker.com
|
||||
```
|
||||
|
||||
The server first inspects the client certificate to extract the subject key and
|
||||
lookup which account it is associated with. The client is now authenticated
|
||||
using that account.
|
||||
|
||||
The server next searches its access control list for the account's access to
|
||||
the repository `samalba/my-app` hosted by the service `registry.docker.com`.
|
||||
|
||||
The server will now construct a JSON Web Token to sign and return. A JSON Web
|
||||
Token has 3 main parts:
|
||||
|
||||
1. Headers
|
||||
|
||||
The header of a JSON Web Token is a standard JOSE header. The "typ" field
|
||||
will be "JWT" and it will also contain the "alg" which identifies the
|
||||
signing algorithm used to produce the signature. It will also usually have
|
||||
a "kid" field, the ID of the key which was used to sign the token.
|
||||
|
||||
Here is an example JOSE Header for a JSON Web Token (formatted with
|
||||
whitespace for readability):
|
||||
|
||||
```
|
||||
{
|
||||
"typ": "JWT",
|
||||
"alg": "ES256",
|
||||
"kid": "PYYO:TEWU:V7JH:26JV:AQTZ:LJC3:SXVJ:XGHA:34F2:2LAQ:ZRMK:Z7Q6"
|
||||
}
|
||||
```
|
||||
|
||||
It specifies that this object is going to be a JSON Web token signed using
|
||||
the key with the given ID using the Elliptic Curve signature algorithm
|
||||
using a SHA256 hash.
|
||||
|
||||
2. Claim Set
|
||||
|
||||
The Claim Set is a JSON struct containing these standard registered claim
|
||||
name fields:
|
||||
|
||||
<dl>
|
||||
<dt>
|
||||
<code>iss</code> (Issuer)
|
||||
</dt>
|
||||
<dd>
|
||||
The issuer of the token, typically the fqdn of the authorization
|
||||
server.
|
||||
</dd>
|
||||
<dt>
|
||||
<code>sub</code> (Subject)
|
||||
</dt>
|
||||
<dd>
|
||||
The subject of the token; the id of the client which requested it.
|
||||
</dd>
|
||||
<dt>
|
||||
<code>aud</code> (Audience)
|
||||
</dt>
|
||||
<dd>
|
||||
The intended audience of the token; the id of the service which
|
||||
will verify the token to authorize the client/subject.
|
||||
</dd>
|
||||
<dt>
|
||||
<code>exp</code> (Expiration)
|
||||
</dt>
|
||||
<dd>
|
||||
The token should only be considered valid up to this specified date
|
||||
and time.
|
||||
</dd>
|
||||
<dt>
|
||||
<code>nbf</code> (Not Before)
|
||||
</dt>
|
||||
<dd>
|
||||
The token should not be considered valid before this specified date
|
||||
and time.
|
||||
</dd>
|
||||
<dt>
|
||||
<code>iat</code> (Issued At)
|
||||
</dt>
|
||||
<dd>
|
||||
Specifies the date and time which the Authorization server
|
||||
generated this token.
|
||||
</dd>
|
||||
<dt>
|
||||
<code>jti</code> (JWT ID)
|
||||
</dt>
|
||||
<dd>
|
||||
A unique identifier for this token. Can be used by the intended
|
||||
audience to prevent replays of the token.
|
||||
</dd>
|
||||
</dl>
|
||||
|
||||
The Claim Set will also contain a private claim name unique to this
|
||||
authorization server specification:
|
||||
|
||||
<dl>
|
||||
<dt>
|
||||
<code>access</code>
|
||||
</dt>
|
||||
<dd>
|
||||
An array of access entry objects with the following fields:
|
||||
|
||||
<dl>
|
||||
<dt>
|
||||
<code>type</code>
|
||||
</dt>
|
||||
<dd>
|
||||
The type of resource hosted by the service.
|
||||
</dd>
|
||||
<dt>
|
||||
<code>name</code>
|
||||
</dt>
|
||||
<dd>
|
||||
The name of the recource of the given type hosted by the
|
||||
service.
|
||||
</dd>
|
||||
<dt>
|
||||
<code>actions</code>
|
||||
</dt>
|
||||
<dd>
|
||||
An array of strings which give the actions authorized on
|
||||
this resource.
|
||||
</dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl>
|
||||
|
||||
Here is an example of such a JWT Claim Set (formatted with whitespace for
|
||||
readability):
|
||||
|
||||
```
|
||||
{
|
||||
"iss": "auth.docker.com",
|
||||
"sub": "jlhawn",
|
||||
"aud": "registry.docker.com",
|
||||
"exp": 1415387315,
|
||||
"nbf": 1415387015,
|
||||
"iat": 1415387015,
|
||||
"jti": "tYJCO1c6cnyy7kAn0c7rKPgbV1H1bFws",
|
||||
"access": [
|
||||
{
|
||||
"type": "repository",
|
||||
"name": "samalba/my-app",
|
||||
"actions": [
|
||||
"push"
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
3. Signature
|
||||
|
||||
The authorization server will produce a JOSE header and Claim Set with no
|
||||
extraneous whitespace, i.e., the JOSE Header from above would be
|
||||
|
||||
```
|
||||
{"typ":"JWT","alg":"ES256","kid":"PYYO:TEWU:V7JH:26JV:AQTZ:LJC3:SXVJ:XGHA:34F2:2LAQ:ZRMK:Z7Q6"}
|
||||
```
|
||||
|
||||
and the Claim Set from above would be
|
||||
|
||||
```
|
||||
{"iss":"auth.docker.com","sub":"jlhawn","aud":"registry.docker.com","exp":1415387315,"nbf":1415387015,"iat":1415387015,"jti":"tYJCO1c6cnyy7kAn0c7rKPgbV1H1bFws","access":[{"type":"repository","name":"samalba/my-app","actions":["push"]}]}
|
||||
```
|
||||
|
||||
The utf-8 representation of this JOSE header and Claim Set are then
|
||||
url-safe base64 encoded (sans trailing '=' buffer), producing:
|
||||
|
||||
```
|
||||
eyJ0eXAiOiJKV1QiLCJhbGciOiJFUzI1NiIsImtpZCI6IlBZWU86VEVXVTpWN0pIOjI2SlY6QVFUWjpMSkMzOlNYVko6WEdIQTozNEYyOjJMQVE6WlJNSzpaN1E2In0
|
||||
```
|
||||
|
||||
for the JOSE Header and
|
||||
|
||||
```
|
||||
eyJpc3MiOiJhdXRoLmRvY2tlci5jb20iLCJzdWIiOiJqbGhhd24iLCJhdWQiOiJyZWdpc3RyeS5kb2NrZXIuY29tIiwiZXhwIjoxNDE1Mzg3MzE1LCJuYmYiOjE0MTUzODcwMTUsImlhdCI6MTQxNTM4NzAxNSwianRpIjoidFlKQ08xYzZjbnl5N2tBbjBjN3JLUGdiVjFIMWJGd3MiLCJhY2Nlc3MiOlt7InR5cGUiOiJyZXBvc2l0b3J5IiwibmFtZSI6InNhbWFsYmEvbXktYXBwIiwiYWN0aW9ucyI6WyJwdXNoIl19XX0
|
||||
```
|
||||
|
||||
for the Claim Set. These two are concatenated using a '.' character,
|
||||
yielding the string:
|
||||
|
||||
```
|
||||
eyJ0eXAiOiJKV1QiLCJhbGciOiJFUzI1NiIsImtpZCI6IlBZWU86VEVXVTpWN0pIOjI2SlY6QVFUWjpMSkMzOlNYVko6WEdIQTozNEYyOjJMQVE6WlJNSzpaN1E2In0.eyJpc3MiOiJhdXRoLmRvY2tlci5jb20iLCJzdWIiOiJqbGhhd24iLCJhdWQiOiJyZWdpc3RyeS5kb2NrZXIuY29tIiwiZXhwIjoxNDE1Mzg3MzE1LCJuYmYiOjE0MTUzODcwMTUsImlhdCI6MTQxNTM4NzAxNSwianRpIjoidFlKQ08xYzZjbnl5N2tBbjBjN3JLUGdiVjFIMWJGd3MiLCJhY2Nlc3MiOlt7InR5cGUiOiJyZXBvc2l0b3J5IiwibmFtZSI6InNhbWFsYmEvbXktYXBwIiwiYWN0aW9ucyI6WyJwdXNoIl19XX0
|
||||
```
|
||||
|
||||
This is then used as the payload to a the `ES256` signature algorithm
|
||||
specified in the JOSE header and specified fully in [Section 3.4 of the JSON Web Algorithms (JWA)
|
||||
draft specification](https://tools.ietf.org/html/draft-ietf-jose-json-web-algorithms-38#section-3.4)
|
||||
|
||||
This example signature will use the following ECDSA key for the server:
|
||||
|
||||
```
|
||||
{
|
||||
"kty": "EC",
|
||||
"crv": "P-256",
|
||||
"kid": "PYYO:TEWU:V7JH:26JV:AQTZ:LJC3:SXVJ:XGHA:34F2:2LAQ:ZRMK:Z7Q6",
|
||||
"d": "R7OnbfMaD5J2jl7GeE8ESo7CnHSBm_1N2k9IXYFrKJA",
|
||||
"x": "m7zUpx3b-zmVE5cymSs64POG9QcyEpJaYCD82-549_Q",
|
||||
"y": "dU3biz8sZ_8GPB-odm8Wxz3lNDr1xcAQQPQaOcr1fmc"
|
||||
}
|
||||
```
|
||||
|
||||
A resulting signature of the above payload using this key is:
|
||||
|
||||
```
|
||||
QhflHPfbd6eVF4lM9bwYpFZIV0PfikbyXuLx959ykRTBpe3CYnzs6YBK8FToVb5R47920PVLrh8zuLzdCr9t3w
|
||||
```
|
||||
|
||||
Concatenating all of these together with a `.` character gives the
|
||||
resulting JWT:
|
||||
|
||||
```
|
||||
eyJ0eXAiOiJKV1QiLCJhbGciOiJFUzI1NiIsImtpZCI6IlBZWU86VEVXVTpWN0pIOjI2SlY6QVFUWjpMSkMzOlNYVko6WEdIQTozNEYyOjJMQVE6WlJNSzpaN1E2In0.eyJpc3MiOiJhdXRoLmRvY2tlci5jb20iLCJzdWIiOiJqbGhhd24iLCJhdWQiOiJyZWdpc3RyeS5kb2NrZXIuY29tIiwiZXhwIjoxNDE1Mzg3MzE1LCJuYmYiOjE0MTUzODcwMTUsImlhdCI6MTQxNTM4NzAxNSwianRpIjoidFlKQ08xYzZjbnl5N2tBbjBjN3JLUGdiVjFIMWJGd3MiLCJhY2Nlc3MiOlt7InR5cGUiOiJyZXBvc2l0b3J5IiwibmFtZSI6InNhbWFsYmEvbXktYXBwIiwiYWN0aW9ucyI6WyJwdXNoIl19XX0.QhflHPfbd6eVF4lM9bwYpFZIV0PfikbyXuLx959ykRTBpe3CYnzs6YBK8FToVb5R47920PVLrh8zuLzdCr9t3w
|
||||
```
|
||||
|
||||
This can now be placed in an HTTP response and returned to the client to use to
|
||||
authenticate to the audience service:
|
||||
|
||||
|
||||
```
|
||||
HTTP/1.1 200 OK
|
||||
Content-Type: application/json
|
||||
|
||||
{"token": "eyJ0eXAiOiJKV1QiLCJhbGciOiJFUzI1NiIsImtpZCI6IlBZWU86VEVXVTpWN0pIOjI2SlY6QVFUWjpMSkMzOlNYVko6WEdIQTozNEYyOjJMQVE6WlJNSzpaN1E2In0.eyJpc3MiOiJhdXRoLmRvY2tlci5jb20iLCJzdWIiOiJqbGhhd24iLCJhdWQiOiJyZWdpc3RyeS5kb2NrZXIuY29tIiwiZXhwIjoxNDE1Mzg3MzE1LCJuYmYiOjE0MTUzODcwMTUsImlhdCI6MTQxNTM4NzAxNSwianRpIjoidFlKQ08xYzZjbnl5N2tBbjBjN3JLUGdiVjFIMWJGd3MiLCJhY2Nlc3MiOlt7InR5cGUiOiJyZXBvc2l0b3J5IiwibmFtZSI6InNhbWFsYmEvbXktYXBwIiwiYWN0aW9ucyI6WyJwdXNoIl19XX0.QhflHPfbd6eVF4lM9bwYpFZIV0PfikbyXuLx959ykRTBpe3CYnzs6YBK8FToVb5R47920PVLrh8zuLzdCr9t3w"}
|
||||
```
|
||||
|
||||
## Using the signed token
|
||||
|
||||
Once the client has a token, it will try the registry request again with the
|
||||
token placed in the HTTP `Authorization` header like so:
|
||||
|
||||
```
|
||||
Authorization: Bearer eyJ0eXAiOiJKV1QiLCJhbGciOiJFUzI1NiIsImtpZCI6IkJWM0Q6MkFWWjpVQjVaOktJQVA6SU5QTDo1RU42Ok40SjQ6Nk1XTzpEUktFOkJWUUs6M0ZKTDpQT1RMIn0.eyJpc3MiOiJhdXRoLmRvY2tlci5jb20iLCJzdWIiOiJCQ0NZOk9VNlo6UUVKNTpXTjJDOjJBVkM6WTdZRDpBM0xZOjQ1VVc6NE9HRDpLQUxMOkNOSjU6NUlVTCIsImF1ZCI6InJlZ2lzdHJ5LmRvY2tlci5jb20iLCJleHAiOjE0MTUzODczMTUsIm5iZiI6MTQxNTM4NzAxNSwiaWF0IjoxNDE1Mzg3MDE1LCJqdGkiOiJ0WUpDTzFjNmNueXk3a0FuMGM3cktQZ2JWMUgxYkZ3cyIsInNjb3BlIjoiamxoYXduOnJlcG9zaXRvcnk6c2FtYWxiYS9teS1hcHA6cHVzaCxwdWxsIGpsaGF3bjpuYW1lc3BhY2U6c2FtYWxiYTpwdWxsIn0.Y3zZSwaZPqy4y9oRBVRImZyv3m_S9XDHF1tWwN7mL52C_IiA73SJkWVNsvNqpJIn5h7A2F8biv_S2ppQ1lgkbw
|
||||
```
|
||||
|
||||
This is also described in [Section 2.1 of RFC 6750: The OAuth 2.0 Authorization Framework: Bearer Token Usage](https://tools.ietf.org/html/rfc6750#section-2.1)
|
||||
|
||||
## Verifying the token
|
||||
|
||||
The registry must now verify the token presented by the user by inspecting the
|
||||
claim set within. The registry will:
|
||||
|
||||
- Ensure that the issuer (`iss` claim) is an authority it trusts.
|
||||
- Ensure that the registry identifies as the audience (`aud` claim).
|
||||
- Check that the current time is between the `nbf` and `exp` claim times.
|
||||
- If enforcing single-use tokens, check that the JWT ID (`jti` claim) value has
|
||||
not been seen before.
|
||||
- To enforce this, the registry may keep a record of `jti`s it has seen for
|
||||
up to the `exp` time of the token to prevent token replays.
|
||||
- Check the `access` claim value and use the identified resources and the list
|
||||
of actions authorized to determine whether the token grants the required
|
||||
level of access for the operation the client is attempting to perform.
|
||||
- Verify that the signature of the token is valid.
|
||||
|
||||
At no point in this process should the registry need to <em>call back</em> to
|
||||
the authorization server. If anything, it would only need to update a list of
|
||||
trusted public keys for verifying token signatures or use a separate API
|
||||
(still to be spec'd) to add/update resource records on the authorization
|
||||
server.
|
||||
77
docs/spec/json.md
Normal file
77
docs/spec/json.md
Normal file
|
|
@ -0,0 +1,77 @@
|
|||
# Docker Distribution JSON Canonicalization
|
||||
|
||||
## Introduction
|
||||
|
||||
To provide consistent content hashing of JSON objects throughout Docker
|
||||
Distribution APIs, a canonical JSON format has been defined. Adopting such a
|
||||
canonicalization also aids in caching JSON responses.
|
||||
|
||||
## Rules
|
||||
|
||||
Compliant JSON should conform to the following rules:
|
||||
|
||||
1. All generated JSON should comply with [RFC
|
||||
7159](http://www.ietf.org/rfc/rfc7159.txt).
|
||||
2. Resulting "JSON text" shall always be encoded in UTF-8.
|
||||
3. Unless a canonical key order is defined for a particular schema, object
|
||||
keys shall always appear in lexically sorted order.
|
||||
4. All whitespace between tokens should be removed.
|
||||
5. No "trailing commas" are allowed in object or array definitions.
|
||||
|
||||
## Examples
|
||||
|
||||
The following is a simple example of a canonicalized JSON string:
|
||||
|
||||
```json
|
||||
{"asdf":1,"qwer":[],"zxcv":[{},true,1000000000,"tyui"]}
|
||||
```
|
||||
|
||||
## Reference
|
||||
|
||||
### Other Canonicalizations
|
||||
|
||||
The OLPC project specifies [Canonical
|
||||
JSON](http://wiki.laptop.org/go/Canonical_JSON). While this is used in
|
||||
[TUF](http://theupdateframework.com/), which may be used with other
|
||||
distribution-related protocols, this alternative format has been proposed in
|
||||
case the original source changes. Specifications complying with either this
|
||||
specification or an alternative should explicitly call out the
|
||||
canonicalization format. Except for key ordering, this specification is mostly
|
||||
compatible.
|
||||
|
||||
### Go
|
||||
|
||||
In Go, the [`encoding/json`](http://golang.org/pkg/encoding/json/) library
|
||||
will emit canonical JSON by default. Simply using `json.Marshal` will suffice
|
||||
in most cases:
|
||||
|
||||
```go
|
||||
incoming := map[string]interface{}{
|
||||
"asdf": 1,
|
||||
"qwer": []interface{}{},
|
||||
"zxcv": []interface{}{
|
||||
map[string]interface{}{},
|
||||
true,
|
||||
int(1e9),
|
||||
"tyui",
|
||||
},
|
||||
}
|
||||
|
||||
canonical, err := json.Marshal(incoming)
|
||||
if err != nil {
|
||||
// ... handle error
|
||||
}
|
||||
```
|
||||
|
||||
To apply canonical JSON format spacing to an existing serialized JSON buffer, one
|
||||
can use
|
||||
[`json.Indent`](http://golang.org/src/encoding/json/indent.go?s=1918:1989#L65)
|
||||
with the following arguments:
|
||||
|
||||
```go
|
||||
incoming := getBytes()
|
||||
var canonical bytes.Buffer
|
||||
if err := json.Indent(&canonical, incoming, "", ""); err != nil {
|
||||
// ... handle error
|
||||
}
|
||||
```
|
||||
Loading…
Add table
Add a link
Reference in a new issue