Polish README (#1)
* Upload eval figures * fix some typos * update model links
This commit is contained in:
parent
66a1bb4602
commit
9adba26a1a
1 changed files with 8 additions and 8 deletions
16
README.md
16
README.md
|
|
@ -5,7 +5,7 @@
|
|||
|
||||
https://github.com/hodlen/PowerInfer/assets/34213478/b782ccc8-0a2a-42b6-a6aa-07b2224a66f7
|
||||
|
||||
<sub>The demo running environment consists of a single 4090 GPU, the model is Falcon (ReLU)-40B, and the precision is FP16.</sub>
|
||||
<sub>The demo is running with a single 24G 4090 GPU, the model is Falcon (ReLU)-40B, and the precision is FP16.</sub>
|
||||
|
||||
---
|
||||
## Abstract
|
||||
|
|
@ -82,9 +82,9 @@ cmake --build build --config Release
|
|||
|
||||
| Base Model | GGUF Format Link | Original Model |
|
||||
|------------|------------------|----------------|
|
||||
| LLaMA(ReLU)-2-7B | [PowerInfer/ReluLLaMA-13B-PowerInfer-GGUF](https://huggingface.co/PowerInfer/ReluLLaMA-13B-PowerInfer-GGUF) | [SparseLLM/ReluLLaMA-7B](https://huggingface.co/SparseLLM/ReluLLaMA-7B) |
|
||||
| LLaMA(ReLU)-2-7B | [PowerInfer/ReluLLaMA-7B-PowerInfer-GGUF](https://huggingface.co/PowerInfer/ReluLLaMA-13B-PowerInfer-GGUF) | [SparseLLM/ReluLLaMA-7B](https://huggingface.co/SparseLLM/ReluLLaMA-7B) |
|
||||
| LLaMA(ReLU)-2-13B | [PowerInfer/ReluLLaMA-13B-PowerInfer-GGUF](https://huggingface.co/PowerInfer/ReluLLaMA-13B-PowerInfer-GGUF) | [SparseLLM/ReluLLaMA-13B](https://huggingface.co/SparseLLM/ReluLLaMA-13B) |
|
||||
| Falcon(ReLU)-40B | [PowerInfer/ReluLLaMA-13B-PowerInfer-GGUF](https://huggingface.co/PowerInfer/ReluLLaMA-13B-PowerInfer-GGUF) | [SparseLLM/ReluFalcon-40B](https://huggingface.co/SparseLLM/ReluFalcon-40B) |
|
||||
| Falcon(ReLU)-40B | [PowerInfer/ReluFalcon-40B-PowerInfer-GGUF](https://huggingface.co/PowerInfer/ReluLLaMA-13B-PowerInfer-GGUF) | [SparseLLM/ReluFalcon-40B](https://huggingface.co/SparseLLM/ReluFalcon-40B) |
|
||||
|
||||
## Inference
|
||||
- If you just have CPU:
|
||||
|
|
@ -107,11 +107,11 @@ Then, you can use the following instruction to run PowerInfer with GPU index:
|
|||
|
||||
## Evaluation
|
||||
|
||||
<img src="/Users/apple/Library/CloudStorage/OneDrive-个人/typora图片/image-20231214203009338.png" alt="image-20231214203009338" style="zoom:50%;" />
|
||||
|
||||
|
||||
<img src="/Users/apple/Library/CloudStorage/OneDrive-个人/typora图片/image-20231214203105378.png" alt="image-20231214203105378" style="zoom:50%;" />
|
||||
|
||||
|
||||
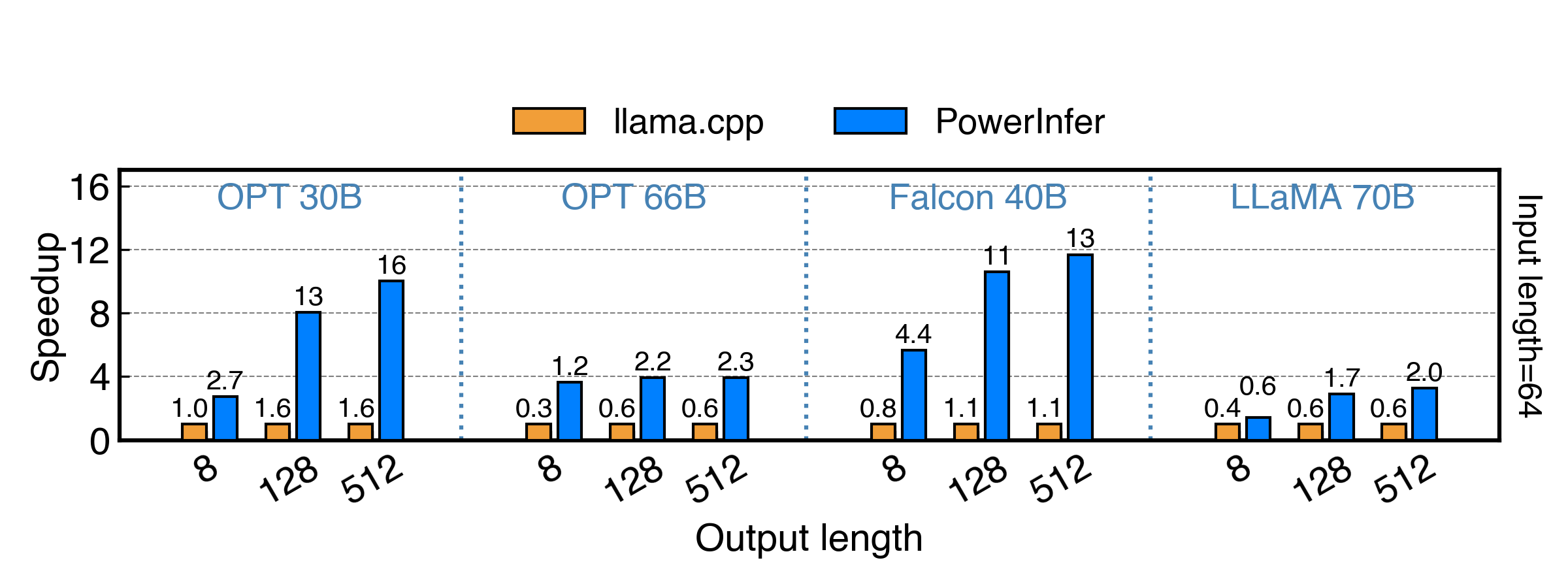
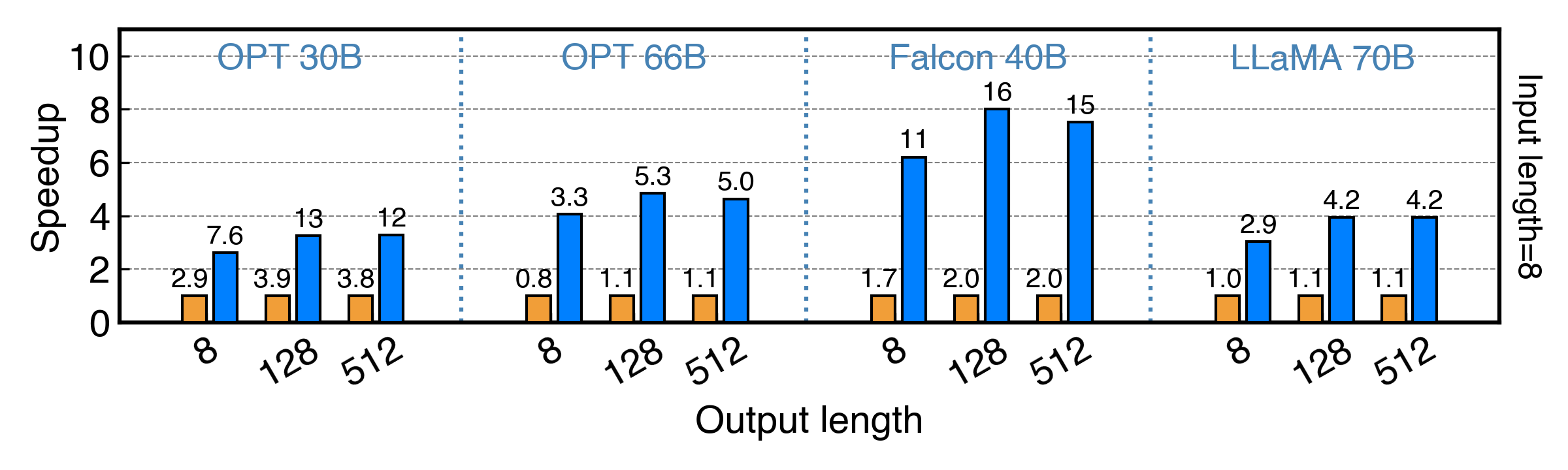
PowerInfer achieves up to 11x and 8x speedup for fp16 and int4 model!
|
||||
PowerInfer achieves up to 11x and 8x speedup for FP16 and INT4 model!
|
||||
|
||||
## TODOs
|
||||
We will release the code and data in the following order, please stay tuned!
|
||||
|
|
@ -130,8 +130,8 @@ We will release the code and data in the following order, please stay tuned!
|
|||
If you find PowerInfer useful or relevant to your project and research, please kindly cite our paper:
|
||||
|
||||
```bibtex
|
||||
Stay Tune
|
||||
Stay tuned!
|
||||
```
|
||||
|
||||
## Acknowledgement
|
||||
We are thankful for the easily modifiable operator library [ggml](https://github.com/ggerganov/ggml) and execution runtime provided by [llama.cpp](https://github.com/ggerganov/llama.cpp). We also extend our gratitude to [THUNLP](https://nlp.csai.tsinghua.edu.cn/) for their support of ReLU-based sparse models. We also appreciate the research of [DejaVu](https://proceedings.mlr.press/v202/liu23am.html), which inspires PowerInfer.
|
||||
We are thankful for the easily modifiable operator library [ggml](https://github.com/ggerganov/ggml) and execution runtime provided by [llama.cpp](https://github.com/ggerganov/llama.cpp). We also extend our gratitude to [THUNLP](https://nlp.csai.tsinghua.edu.cn/) for their support of ReLU-based sparse models. We also appreciate the research of [DejaVu](https://proceedings.mlr.press/v202/liu23am.html), which inspires PowerInfer.
|
||||
|
|
|
|||
Loading…
Add table
Add a link
Reference in a new issue